Gridlock, Monikers, and CPU-per-user
Team Gridlock continues to work hard against the demons of fleet lag and could-do-better code. At the end of April we activated a couple of optimisations on Tranquility, and now we've had a few weeks of operation, we can see some measurable results. After sharing these results with the CSM during their recent summit visit, we decided to release them to an even wider audience. So, stand by for some more graph-and-pseudo-code porn.
First a graph, because everybody loves graphs:
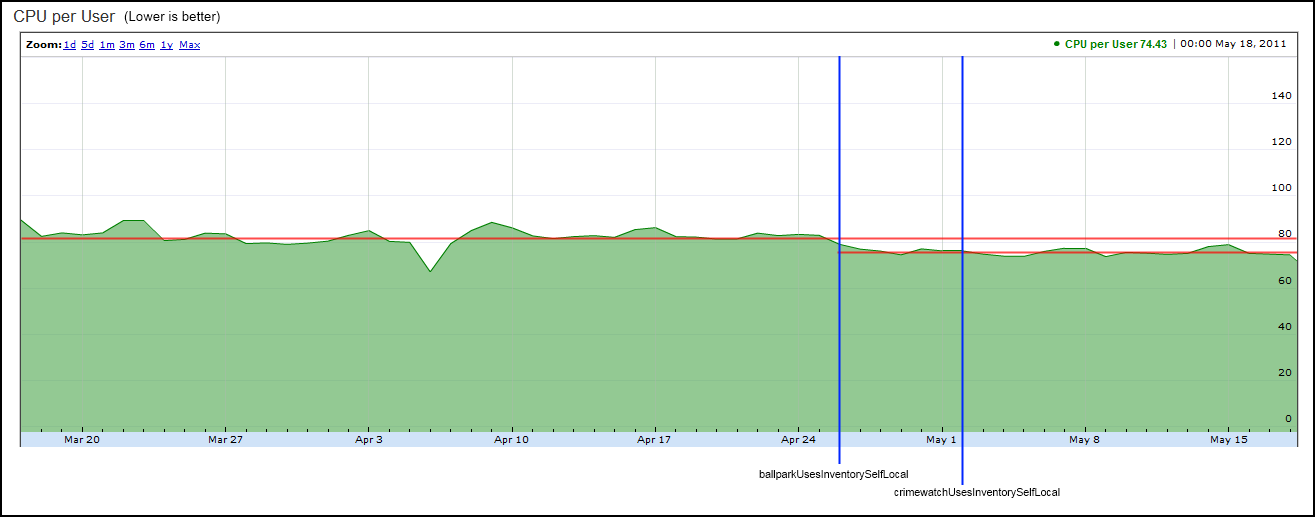
Click image to enlarge
What I'm showing here is the CPU-per-User metric across all Tranquility server nodes over a period of eight weeks. The vertical scale is of somewhat arbitrary units, but is consistent providing the hardware remains constant. This metric basically shows how much computer power we are burning for each connected user at any given time. The lower this number gets, the better. The red horizontal lines show the trend before and after the changes, whilst the blue lines show the dates of the changes. The changes are labelled by the actual names of the flags we used in the code. (This dev-blog itself is based on an internal report I wrote-up, so I'm going to keep it as similar as possible)
Each flag enables a particular optimisation, without requiring a patch to the server. This is good as we can turn on the flag for a subset of nodes and then monitor those closely for undesirable fallout, before later turning it on cluster-wide.
The flags
On April 26th, we activated a server flag 'ballparkUsesInventorySelfLocal'. In the days after this change, the CPU-per-User metric across the whole cluster dropped by approximately 8%. This is a pretty nice win, for what was actually a very small change in terms of lines-of-code altered. (There was still quite a lot of work homing in to figure out the change in the first place, and then a fair bit of testing and profiling afterwards to verify it)
On May 2nd we activated a server flag 'crimewatchUsesInventorySelfLocal'. This didn't make much change to the overall CPU-per-User, but that is expected. I expect the gains from this flag would only be noticeable in the specific cases of fleet-fights and low-sec, so they won't show up when averaged across the whole cluster.
If all you're interested in is seeing that we're still making progress in The War Against Lag, then you can stop reading here. The graph above shows everything you need to know. The hamsters are 8% happier. If you're more curious about what actually changed, keep going.
A moniker primer
Both changes were along the same theme: Replacing a moniker to a bound-object with a direct reference to that object. What does that mean? Well, gather around the whiteboard. I'm going to explain a lot of stuff, and then show why getting rid of that stuff is sometimes a good thing to do.
The main communication mechanism between server components is via monikers and bound-objects. A moniker is a handle to a bound-object. A bound-object is a frontend to a component, and is responsible for keeping track of how many monikers are pointing to it. This is basically an implementation of the proxy design pattern.
Things get interesting when you realise that the moniker and the bound-object can be in different processes. They can even be on different server nodes. (The Tranquility server cluster is currently made up of around 200 nodes.) In fact, they can even be on opposite sides of the Earth - your EVE client uses the same tools for interacting with objects on our servers. Programmers will recognise this as an implementation of an RPC mechanism. This is great as it means we can distribute logical parts of the server on to different nodes, and they can communicate using a programming interface that is almost identical to if they were on the same node. Monikers do come with a performance cost however - every access through a moniker requires a few extra checks and look-ups compared to a regular function call. This overhead is because of the extra features that monikers provide, such as lifetime-management (what happens if either end of the connection goes down, or one of the objects is destroyed?), call synchronisation (I can make sure that there are never two concurrent calls into the same bound-object, for example), and per-function permission controls (any user can call function A, but only a GM can call function B)
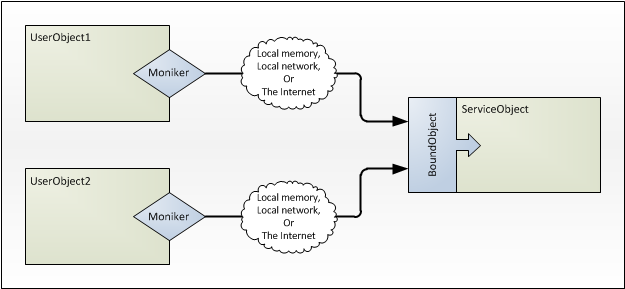
The diagram above shows a generic object 'ServiceObject' that is being accessed by two user objects. Each access is via a Moniker, and all the incoming Moniker connections are looked after by a BoundObject interface. The black arrows indicate the logical connections, which could either be in the same memory space, between machines in the same local network, or ever across the internet.
Putting it into action
Within the server, each solar system is handled by a number of inter-related components. The three components related to this discussion are called Ballpark, CrimewatchLocation and InventoryLocation. For each solar system, there is a particular instance of each of these. Ballpark handles stuff in space (such as the Destiny physics engine, sending state updates to clients, jumping through gates and lots more). CrimewatchLocation tracks aggression-flagging, war rules, kill-mails and CONCORD spawning. InventoryLocation tracks what item is located where, and acts as a front-end to the item database.
The InventoryLocation for a given solarsystem is available from any other node via a moniker, providing you know the ID of the node hosting it, and have suitable permissions. The Ballpark and CrimewatchLocation game systems were using this facility, and accessing the InventoryLocation via a moniker object.
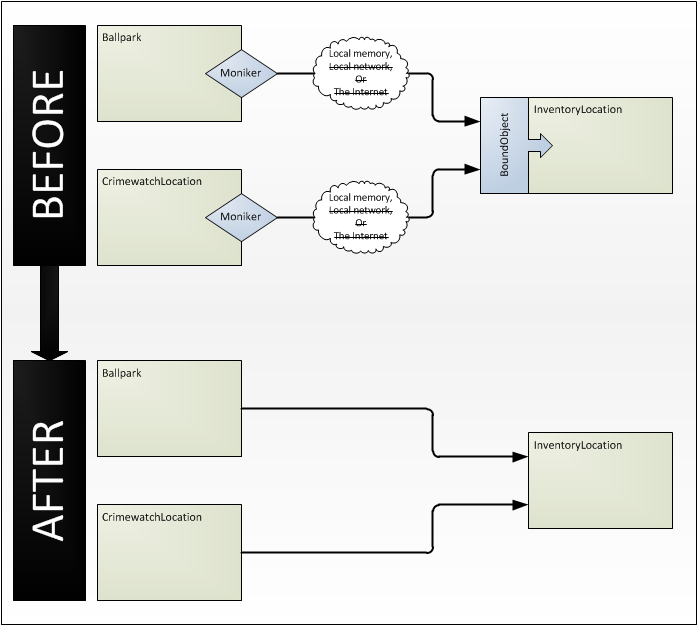
This diagram shows the connection between the Ballpark, CrimewatchLocation and InventoryLocation objects before and after the change. In the before case, the moniker connections were constrained to being in the same process due to shared dependencies on other objects.
This is great. At first glance the desirable approach might be to move each component onto its own node, attempting to make gains via parallelism. However, for any solar system, these three components have always lived together on the same node. Over time they have grown roots into each other via other, non-monikered, components. As such, separating them out is a major undertaking. In effect, Ballpark, CrimewatchLocation and InventoryLocation have become such close friends that they share a few organs. They are also very chatty between each other, so without significant restructuring, the communications overhead of their interactions might massively outweigh any savings due to parallelism.
Refactoring to eliminate these links is still something we want to do, but there are other, lower-hanging fruit that can give us good bang-for-buck.
The fix
So, we have three components communicating via an RPC mechanism, yet they always live together. After establishing that the overhead of going through monikers was noticeable, I set about removing this intermediate step. Changing the moniker to a direct reference was easy enough - it already has functionality to do that.
Here's what the change looked like
Before:
At initialisation:
# Get the moniker to an inventory location:
inv = GetInventoryMoniker(solarsystemID)
During runtime:
# Use the inventory to get stuff from the DB:
item = inv.SelectItem(itemID)
After:
At initialisation:
# Get the direct reference to an inventory location: inv = GetInventoryMoniker(solarsystemID).GetSelfLocal()
During runtime:
# Use the inventory to get stuff from the DB:
item = inv.SelectItem(itemID)
That's it. Fifteen extra characters, which disable a piece of functionality, for an 8% saving across the cluster. Not bad, huh?
The fix for the fix
But wait! Remember how I mentioned earlier that moniker also does some useful things in addition to providing an RPC mechanism, such as lifetime management by reference-counting? Bound-objects only live as long as there are monikers somewhere in the world referencing them. Take away the last moniker and the bound-object is cleaned-up and removed. This was a problem we discovered during testing. It turns out that CrimewatchLocation's moniker to InventoryLocation was the only thing keeping it alive. This led to some strange bugs where a solar system would be fine as long as someone had aggression flags, but once there was nothing for CrimewatchLocation to do, a sequence of events would lead to InventoryLocation shutting down even if Ballpark was still using it via a direct reference.
Once we'd found and fixed this issue, we went through a series of mass-tests with the flags enabled, and also let it soak on Singularity for a while to flush out any other edge cases.
Conclusion
Once we had satisfactorily finished the testing phase, these changes were deployed to Tranquility in an inert state. At the end of April, we had a quiet week (in that no hotfix changes were scheduled for release) and so activated the changes - firstly to Ballpark on 26th April, and then to CrimewatchLocation on 2nd May. We chose this time because the lack of any other changes meant we could observe any gain (and possibly any fallout) in isolation, and easily revert by disabling one or both optimisation flags.
After a few days, the numbers on the CPU-per-user graph were looking good, and we hadn't seen any adverse issues. A few weeks later, we had enough data to make the claim of a cluster-wide 8% saving from just an extra 30 characters of code (not counting fixing up some object-lifetime issues). Pretty good, huh?
This story is an example of some of the work that Gridlock does. We also do things like organise the mass-tests, profile up-and-coming features from other teams to make sure we're not going backwards, and look to the future with plans such as improved live-remapping (where we take a solar system featuring a fleet-fight, and move it on to a dedicated node) and Time Dilation.
