Tranquility Tech III
On behalf of the Operations Team, and with blog writing music blasting on full (Skálmöld), I am privileged to be telling you about a huge project called Tranquility Tech III, which we plan to complete by early 2016.
The project is called TQ Tech III (TQ is short for “Tranquility”, the live server for EVE Online) because this is the third time the EVE infrastructure is physically moved, and CCP is now also making a significant investment in all new hardware (Network, Storage, and Servers) whilst moving it all to a new hosting facility within London.
We’ve accomplished such a herculean task a few times in the past. Here’s a quick trip down devblog memory lane to remind you:
- 2010 - TQ Level Up
- 2011 - TQ Database Upgrade
In the continued commitment to EVE Forever, it is time for TQ to level up again, with new methods and technology having emerged to help inform us in our approach to running the super-complicated service and game and universe that is New Eden.

TQ Tech III has a many highlights which I’ll go over and enlist fellow devs to explain.
Warning: It’s about to get super tech-freaky up in here!
Added Redundancy
TQ’s storage is mirrored and redundant. The storage array has always been redundant but now we’ve added more failsafes.
There will be a full SAN mirror so that we can both maintain TQ and failover live, replicating a copy of the TQ Database across the ocean to Iceland, land of fire and ice.
From the storage side this is how TQ will look once we're done:
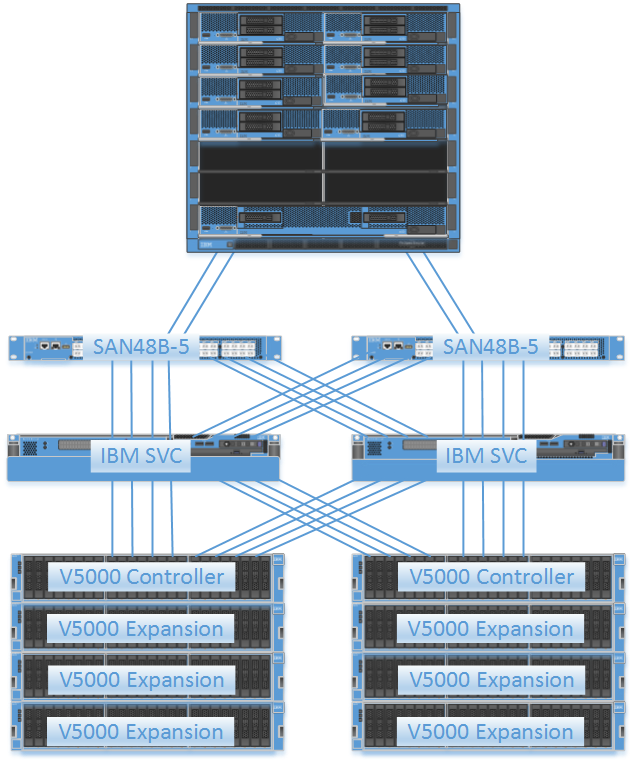
What you see here are 2x IBM SAN volume controllers which govern and control 2x IBM V5000 controllers which store all the data with 3x expansion shelves that house 9x800 GB SSD's with a grand total of 83x 1.2TB 10K SAS disks.
Remember this is all mirrored so double these disk numbers for the full picture!
All this lightning fast and redundant storage has to talk to servers...
The New Servers
Since day one, EVE has been operated by IBM blade servers. For the upgrade we chose the next generation of IBM servers called IBM FLEX.The above picture demonstrates 1x FLEX Chassis connections to its storage
The FLEX concept is similar to the blade centers in that there is a chassis which has power and cooling and you can have up to 14x nodes in each chassis.
In comparison, the current TQ blade centers run on 4x 1Gbit network connections then each of the 14x blade has access to 2x1GB as they have 2x network cards.
The new IBM Flex chassis will have 4x 10Gbit network connections, giving each flex node access a total of 2x 10Gbit throughput.
For the current way that EVE runs this is an overkill but having this in place allows for our engineers to test out interesting new ways to scale TQ and architecture performance, that will take time of course but the immediate benefit is that our deployment times will speed up a lot!
Also this will drastically improve our virtual server environment for example when we live migrate Virtual Machines across physical hosts.
Oh yeah, we will have 6x chassis btw :D


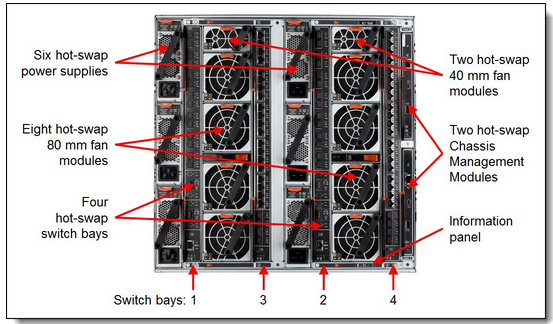
Isn't she a beauty?
You can see a lot of redundancy in the internal components, which is planned so we can maintain TQ by swapping a whole chassis out of rotation while EVE players continue to battle, trade, chat, manufacture, explore, and scam on the other 5.
The servers are connected to the storage via 2498-F48 IBM SAN 16Gbit Switches with everything cross-connected so there is no single point of failure.
The Mahālangūr Himāl
Today we have one server which we call the “Everest” node. It is assigned to all the most prolific high–load EVE situations, typically the biggest fleet battles in all of gaming.
With TQ Tech III there will be 6x Everest Nodes.
That leaves a lot of potential for a lot of spaceships to explode at the same time. It also means that certain alliances can forget to pay several crucial bills at one time if they so choose!
The Sexy TQ Database Machine
Let’s take a deeper look at the cluster, starting with TQ's database machines.

The 4x Microsoft SQL Database machines will have a whopping 768GB of RAM each running on 1866MHz. They have 2 Intel E7-8893 v3 - 3.2GHz CPU's with 4 cores (8 hyper-threaded) and 45MB cache which are ideal for database-intensive workload.
To go into little bit more detail on the DB side, here are some notes from the Database Administration team.
The Database Clusters
Currently we have three main production DB clusters:
- TQ (2x cpu w/ 32 Hyper Threaded cores)
- Web (2x cpu w/ 24 Hyper Threaded cores)
- Account Management and Payment (2x cpu w/ 24 Hyper Threaded cores)
All three are on very different types of hardware, spanning multiple generations of architecture, and mostly held together with Minmatar duct tape, soulful Amarr prayers, the naïve and hopeful Gallente spirit, and low-grade mass-produced Caldari chicken wire from upgrades over the years.
With our New TQ cluster, we're looking to consolidate and free up physical space so we'll be combining Web and Account Management and Payment clusters while we keep TQ separate.
For CPU's we are upgrading from ancient 5 year old X7560's @ 2.26 GHz to brand spanking new E7-8893 v3's @ 3.2 GHz. That's a 45% increase in clock speed alone, and on top of that we get a huge 75% increase in memory bus speed by going from 1066 to 1866!! Make no mistake, we need all that extra memory speed as we go from 672GB of RAM to 1.5TB, yes you read that right - 1.5 TERA bytes of RAM! That’s how we roll these days, we count our TQ hardware memory in terabytes!
Keep in mind these numbers are just from active nodes, so the New TQ DB cluster total is double this when we factor in the secondary / passive nodes. 3 TB of RAM for our 2 production DB Clusters--mmmmm, tasty!
While we had discussed having a single two node Active-Active cluster, we decided against this for various reasons. For example, with one cluster.exe crash the whole shebang could go down. Having the TQ DB cluster isolated gives us great peace of mind across the whole system.
With that said, we have 4 amazingly powerful DB machines to host our two clusters and have come up with a very interesting plan in an attempt to maximize redundancy.
Virtualize All The Things!

Before we go further, keep in mind that this is a proof of concept that we have yet to test. It is entirely possible we'll ditch this and just go with plain normal clusters (that still happen to be running on insanely UltraMegaShiny hardware from the heavens).
Our plan is to create a 4 node ESXi cluster farm with the 4 monster nodes. On top of the hypervisor we'll build both of our SQL Server clusters with one cluster node per ESXi server - as if they were physical. No real change there!
But...
The real benefit comes into play when (or if, but more likely when) one of these physical hosts needs hardware maintenance or needs to be taken offline for some reason. At this point, in a typical two-node physical cluster we would be forced to run on only one cluster node and have fingers crossed that our now-single-point-of-failure does not fail. Lots of soulful Amarrian prayers would be required.
With our virtual direction, we could simply vMotion the passive cluster node from its dedicated ESXi host to another ESXi host (the one hosting the 2nd cluster’s passive node)...and Bob’s yer uncle! Sure that one host with two passive nodes will now be over-allocated, but we would have to lose two more hosts before that becomes an issue!
This means that not only are we redundant on the SQL Instance level by using Windows Failover Clustering, but we'll now be able to survive more than one hardware failure as well! We have a lot of testing to do with this but for the most part this is all proven tech, so really, what could possibly go wrong?!
Yours always!

CCP DeNormalized, CCP Hunter, CCP Stephanie, and CCP Jolin
Back To The Cluster!
Specs of Current TQ Tech II vs TQ Tech III
|
Node role |
TQ Tech II |
**TQ Tech III ** |
|---|---|---|
|
Standard SOL Nodes |
51 x IBM HS21XM - Intel X5260 CPU @ 3.33GHz with 32GB RAM (1333MHz) |
30x IBM x240 - Intel E5-2637-V3 CPU @ 3.5GHz CPU with 64GB RAM (2133MHz) |
|
Enhanced SOL Nodes |
9 x IBM HS23 - Intel Xeon CPU @ 3.30GHz with 64GB RAM (1333MHz) |
6x IBM x240 – Intel E5-2667 v3 CPU @ 3.2GHz with 128GB RAM (2133MHz) |
|
Everest Node |
NDA |
N/A |
|
DUST514 Proxy Node |
4 x IBM HS22 - Intel X5687 @ 3.60GHz with 24GB RAM (1333MHz) |
Will run on Eve proxies |
|
EVE Proxy Node |
5 x IBM HS23 - Intel E5-2643 0 @ 3.30GHz with 64GB RAM (1600MHz) |
6x IBM x240 - Intel E5-2667 v3 CPU @ 3.2GHz with 128GB (2133MHz) |
|
ESXi / Virtual hosts |
4x IBM HS 22 - Intel E5620 @ 2.4GHz 146GB RAM (1333MHz) 3x IBM HS 22 - Intel E2640 @ 2.6GHz 146GB RAM (1333MHz) 2x IBM HS 22 - Intel X5690 @ 3.4GHz 96GB RAM (1333MHz) |
6x IBM Flex x240 Intel E5 2640 v3 @ 2.6GHz 386GB RAM (2133MHz) |
|
Database Server |
2x IBM X3960 X5 – Intel X7560 @ 2.26 GHz with 512GB RAM (1066 MHz) |
2x X880 X6 FlexNode – Intel E7-8893 V3 @ 3.2 GHz with 768GB RAM (1866 MHz) |
Network Upgrade
At this stage, we have talked a lot about fast servers with a ton of fast storage. But something needs to connect that all together and then to the place with all the funny cat pictures (the Internet). Otherwise EVE Online is not so much... online.
Over to our Network Team for more info.
At the network edge, our trusty Cisco 7606 routers have served us well since 2009. We peer with over 20 providers and get full BGP tables from five of them, making for a total of over two million path attribute entries that get compiled into the half-million global BGP best-path route table on each edge router. These venerable beasts of the routing world have been handling all of that without breaking a sweat.
Still, technology has moved forward in leaps and bounds during the last six years, and it's time to retire those old routers and replace them with a new generation. In order to best serve you, the glorious pilots of New Eden, we are once again investing in the best and the greatest. TQ deserves nothing less!
The new boxes are a whole order of magnitude more powerful, offering throughput of 120Gbps and more than double the memory, allowing us to peer with more providers. The extra RAM also allows them to keep pre-calculated backup BGP routes in memory for every active route, so that a failed path may be switched to a secondary path in a matter of few milliseconds. That means that if a directly-connected provider fails, most players routed via that provider get switched to a new provider without being disconnected. The new routers will allow us to provide better connectivity while opening a whole new universe of possibilities with their new features, doing so with expanded memory and processing power.
Other fundamental part of TQ’s current edge network are Cisco ACE 30 load-balancers. As quirky as those boxes have been to configure, they have a special place on our technology-loving hearts here at CCP as they have allowed us to rapidly deploy major changes to TQ and have proved to be rock-solid.
However, a couple of years ago Cisco pulled out of the load-balancing market and left the ACE as a moribund platform dying a slow death. Since then we have been testing different platforms and are excited to have found a great replacement that brings improved performance as well as a whole new bag of tricks.
In performance terms alone, with New TQ we are increasing throughput from 16Gbps to 30Gbps and maximum concurrent connections from 4 million to 24 million. The new load-balancers have gotten all of us, not only in OPS but also in EVE Development, rubbing our hands with glee like a capsuleer who just got their hands on their first Titan.
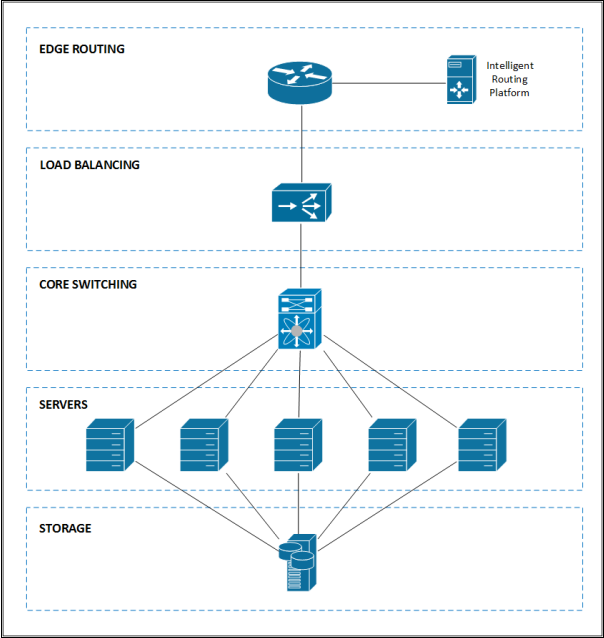
Player Connectivity
We are not just replacing old hardware with new, but also looking at what more can be done to improve the player experiences with regards to connectivity. As part of that effort, we will be deploying a new Intelligent Routing Platform to optimize BGP routing. This system will automatically test both latency and packet loss to every single player upon connection to TQ, running tests simultaneously over each of our connected providers and peers back to the player's ISP (Internet Service Provider).It will also non-disruptively switch each connection to the best available path.
Active connections get tested every few hours. This system has proven to be able to seamlessly bypass many problems and blackouts that regularly afflict the rough seas of the Internet. The excellent reporting will also allow us to tailor our selection of providers to the ones that perform best for EVE players.

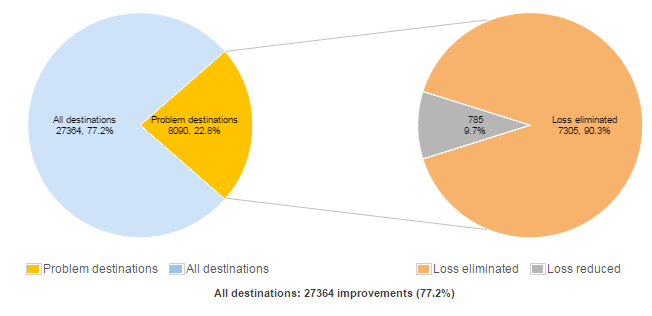
On our tests, as you can see on the charts above, the Intelligent Routing Platform was able to improve on connections to over 7,000 ISP networks worldwide, eliminating packet loss in 91% of connections to TQ where packet loss existed, and bypassing blackouts on internet routes in 59% of cases. Latency is also much improved, with reduction of at least 20% in more than half of the high-latency connections. Those are the types of metrics we love to see!
Finally, we will continue to expand our peering with LINX, the London Network Exchange, which allows us to peer directly with a large number of ISPs. That way, players connecting via those ISPs can reach TQ directly, without crossing any additional networks on the public internet, cutting down on the number of hops and offering a much more stable connection.
We would love to tell you all about the specs of these new boxes in mind-numbing details (we can talk about that endlessly, believe me!), but our security specialists tell us that we must keep most of that secret. But, but, but, if you come to the OPS discussion roundtable at the next EVE Fanfest, we promise to share with you glimpses of this wonderfully new and improved world of Internet spaceship networking.
- CCP Lucca and CCP Skylark
A Modern Home
TQ started in a hosting center called Cable and Wireless in London, then moved across the street into Telecity in February 2006. Now, about a decade later, it is time to move to a new data center (opened in 2014) with the latest design in the data center industry.
For couple of months we will have both sites operational in parallel. Then, when we are ready, we will swap over with the goal to have as short of a downtime as possible.
We aim to have TQ Tech III up and running in very early 2016.
Then we will relocate what is soon-to-be-known-as “Old TQ” back home to Iceland to another data center with Verne Global (which is powered by mysterious geothermal volcano power).There we will host all the test servers like Singularity (Sisi), Multiplicity, etc with the best bits from Old TQ, plus some upgrades.
Starting then, we will begin replicating New TQ’s database from London to Iceland so we have a secondary site capable of taking over in case Ragnarök happens and is centered in England.
You can expect another blog in beginning of November with pictures of the hardware being installed in Reykjavík and a progress report.
We in the Operations department are truly excited and proud of the TQ Tech III and what it means for EVE Online and its players.
That's enough writing it for now. Time to get back to the project!
- CCP Gunshow, on behalf of the CCP Ops Team
