Fixing Lag: Drakes of Destiny (Part 2)
Previously...
In the first part of this blog, I talked about what Destiny is, and showed how a tool called Telemetry is helping us visualise where we should focus our efforts to improve server performance. I ended with a highlight of a particular problem - missile spamming Drakes causing excessive Destiny load.
This time, I'm going to show how I changed the situation for the better.
I'm going to begin at the end. Or, more specifically, I'm going to show the results. Figure 1 shows the overall allocation of CPU time during 100 seconds of missile spam. (For the specific setup used in the test, see the first part of this blog). The left column shows where the time was spent in the old code, as it has been on TQ for a long time. The right column shows the new improved version, released with Incursion.
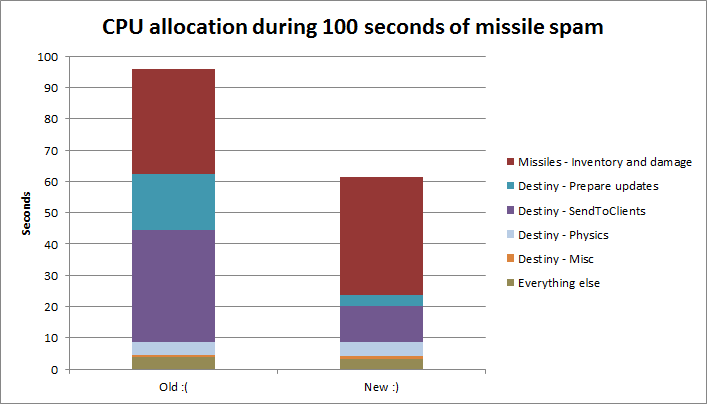
Figure 1: Total CPU load over 100 seconds - before and after the change
As you can see, the Destiny load has been substantially reduced. Inventory and damage has now become the single most expensive area - we have already got some promising improvements in the development pipeline for this, but those are for another day.
So, how did this happen?
Warning: Pseudo-code ahead!
One of the first things that Destiny does each tick is build lists of added and deleted balls for each observer. For each added ball, we also have to get extra data, such as corp ID, security status, visual effects (such as Sensor Boosters) as well as the actual dynamic state (position, velocity and so on).
Vastly simplified, the algorithm for doing this looked something like:
1: for every observer: # (ie a user's ship)
2: for every ball in the observer's bubble:
3: if ball was added/deleted to the bubble in the last tick:
4: gather up all the data required to tell the observer's client about this ball
If you think about this for a while, it might become obvious why this scales so badly - O(n*m) is bad when n or m gets large. When you consider that step 4 always produces the same data for a given ball, regardless of who the observer is, you realise this is also incredibly wasteful.
The first optimisation was to add a cache to step 4. For reasons I don't have space to explain, this actually benefits fleet warps more than stationary engagements. It also doesn't get rid of that awful nested loop.
The next optimisation was to refactor the algorithm. At this point, I want to detour slightly to address another common concern: Why do you use Python? Python is slow. If you ported everything to C++, there would be no more lag. Well in this case, I have to disagree with those statements. The function in question was responsible for over 15% of the entire CPU load in some mass-test I have monitored. It was also written entirely in C++. The fact is that a sub-optimal algorithm can be significantly more costly than any overhead due to language choice. For low numbers of observers/balls, the algorithm described above is perfectly reasonable. However as we push bigger numbers at it, it is going to scale in a very poor manner.
The new-and-improved version of the function now looks something like this (again, vastly simplified):
1: for every bubble:
2: create a list to track adds/deletes:
3: for every ball in the bubble:
4: if ball was added/deleted to bubble this frame:
5: gather up all the data required to tell a client about this ball, and store in the list
6: for every observer: # (ie a user's ship)
7: store an index into the list created in step 2, based on observer's current bubble
This now scales much better as the number of balls and observers rises - it is more like O(n+m).
The other area of Destiny load I identified previously was the overhead of serialising the updates for each client. Solving this was one of those epiphany-in-the-shower moments that could only happen after I'd made the changes above: Most clients in the same bubble will received a serialised update containing the same information. Why serialise that information for every single client, when I have already determined the part they all have in common? After we've completed step 5, we can pre-serialise the update once, and simply pass that same blob of data to every single client in a given bubble. Previously we did one serialise operation per observer. Now we do one serialise operation per bubble, followed by one memcpy per observer. (This is vastly simplified - there are still edge cases that this doesn't cover, but those are in the minority)
The valley of many Awesomes
The improvements are written in such a way that I can toggle them on and off whilst the system is running live. This graph of CPU load across time shows the effect of turning the optimisation on and off:
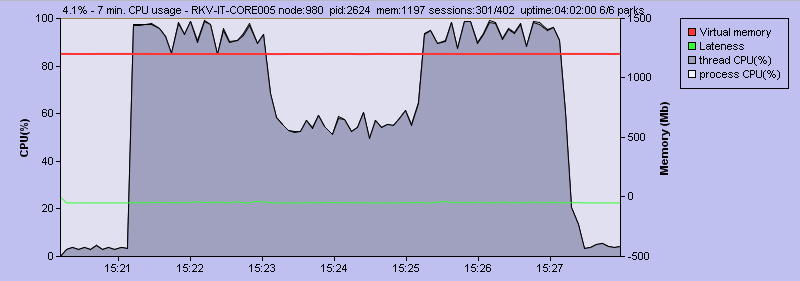
Figure 2: CPU load during missile spam, whilst toggling the optimisations on and off
Missile spam starts at 15:21, and they run out of ammo at 15:27.
Initially the optimisation is switched off. At 15:23, I switch it on (CPU drops dramatically). At 15:25, I switch it back off (CPU rises back up)
For comparison, here are some Telemetry traces of Destiny ticks with the optimisation off and on:
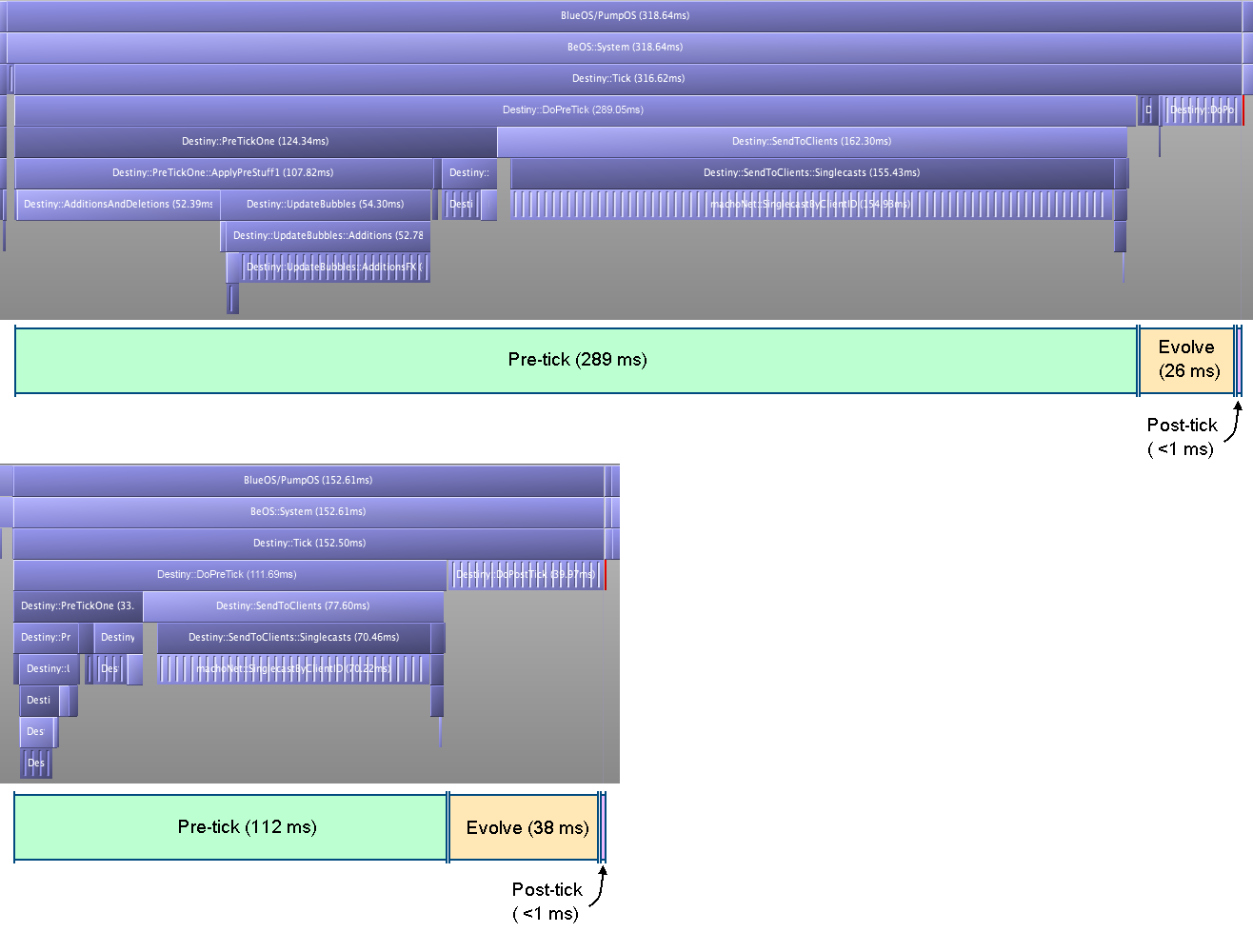
Figure 3: Comparison of two Destiny ticks, before and after the optimisation (horizontal scale is the same)
The upper trace was taken just before 15:23, and the lower one just after 15:23.
Deployment
These changes were running on Singularity during October/November. If you were present at some of the mass-tests, you may recall how we organised multiple fleet-warps, gate-camps and POS bashes in order to exercise this new code. This proved very useful to validate that my experimental results were still applicable in a real situation with real users.
Client support for the new pre-serialised updates was deployed with Incursion 1.0.0 on November 30th. On December 1st I activated the new Destiny code on a small number of Tranquillity nodes, and closely monitored the affected systems. Once we were happy everything was running correctly, the changed was activated for all systems during downtime on December 2nd.
Hopefully you've found this behind-the-scenes look at Destiny interesting. If so, let us know and we might do more. Feel free to ask questions in the discussion thread - I'll keep an eye on it and try to answer what I can.
