Tranquility Tech IV
There is an age-old question facing all capsuleers: If you replace your spaceship one spare part at a time, when is the ship completely new and no longer the original?
That’s where we find ourselves now with Tranquility hardware. Nothing remains of Tranquility Tech III - the current cluster is entirely Tranquility Tech IV.
As part of continually evolving and modernizing EVE, we keep improving Tranquility’s technology to achieve better performance. The end goal is to ensure that it lasts forever, in turn making your experience in New Eden a continuously exciting one.
In early 2016 new hardware for Tranquility was deployed after months of preparation. Since then, several changes have been made; hardware upgraded and superseded, and a number of fixes implemented but not many hardware-specific blogs have been published.
So let’s amend that and go on a journey together.
Upgrading the universe
Back in the day, EVE Online was fully on-premise in a datacenter in London, with a few external services such as the Login Server, also on-premise in that same datacenter. The EVE Launcher would update the EVE Client from a CDN, the EVE Client would connect via loadbalancers to PROXY nodes, which would in turn connect to SOL nodes, which would use a Microsoft SQL Server database as their backend - both for some of the business logic but primarily for storage. Everything was in our London datacenter and the universe was in a single database.
ℹ️ The difference between PROXY nodes and SOL nodes in the Tranquility cluster is mostly that session management is on the PROXY nodes even if some processing happens there as well (e.g. there is a dedicated market proxy service that fronts the market sol service). But there was also an intended architecture of the PROXY nodes being spread across the world with dedicated network backhaul. Instead, we eventually ended up moving the London datacenter’s network behind Cloudflare’s network services in early 2020, after adjusting our DDoS protection for over a decade, using Cloudflare since then as the front door.
Fully describing Tranquility Tech IV’s Ecosystem today is not simple. EVE Online now spans across the on-premise cluster and services and also various cloud services that both the EVE Client and Tranquility connect to: this includes Chat, Search, Image Server, a message bus with multiple gateways, and a whole host of smaller domain services, each one with a targeted scope. In addition, there are fully external services such as Project Discovery.
A number of changes were made between 2016 and 2020; mostly moving the network behind Cloudflare, adding Intel Gold 5122 and Gold 5222 powered machines to the cluster and deprecating Intel E5-2667 v3 powered machines. But then a large portion of the hardware changes happened between October 2021 and February 2023.
In 2021, the storage in our London datacenter and the game database machine (both its hardware and SQL Server version) were upgraded. The new storage is an IBM Flash System 7200 that uses NVMe-attached drives (there are no more spinning disks now; does that mean that the space hamsters are gone?) and the new database hardware is comprised of two Dell EMC PowerEdge R750 machines (primary/standby pair), each one a dual-CPU Intel Gold 6346, each CPU with 16 cores (hexakaideca), with 4 TB of memory. The setup is fully redundant and looks like this:
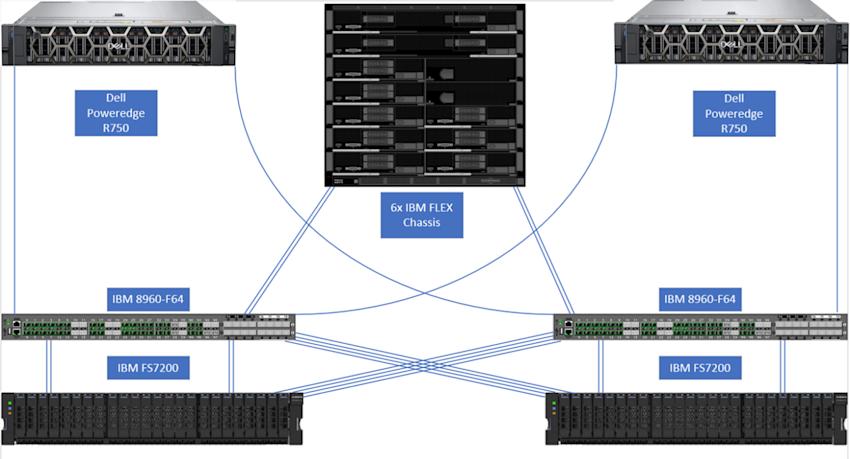
You can read about all the details on the new storage and the new database machine in this devblog and take a look at the 4 TB of memory in the new database machines shown below:

ℹ️ The old database hardware were magnificent beasts of a different era. After the datacenter move in 2016, the game DB was running on two machines (primary/standby pair) with E7-8893 v3 CPUs and there were another identical set of machines for other databases. It became clear that a single such machine wasn’t enough for the game DB, but since that other set of machines was effectively idling they were joined together. As in, literally joined together physically with a special clip. Lenovo calls this QuickPath Interconnect (QPI). Out of the four machines we then got a set of primary/standby 'machines' where each one was actually two machines joined together and acting as one. There was a dramatic video of this at Fanfest 2018.
A speedier and more reliable startup
Let’s wander off the path here for a moment and talk about software.
The old database hardware was two machines joined together and each one a dual-CPU system and therefore the 16 cores were split into four NUMA nodes with very different memory access latency. Each set of 4 cores would have its local memory, then the remote memory in the same box (attached to the other CPU), and finally the remote memory across the QPI (attached to the CPUs in the other box).
We would sometimes encounter what we called “The NUMA Node Issue”, where during startup after downtime - especially after a primary/standby failover when the cache would be empty - one NUMA node, one set of 4 cores, would become incredibly busy for an extended period and the other 12 cores would almost be idling. Yet the game cluster was hammering the database with requests and barely making the startup due to the delayed response from the busy database. That was fixed with software changes in August 2020, by changing the DB connection data structure from a stack to a queue and cycling through available DB connections instead of
using the most recently used connection. This distributed the load more evenly across all four NUMA nodes. Still, when selecting new database hardware, the focus was on reducing the number of NUMA nodes and the new machines have two NUMA nodes (the memory attached to each CPU socket) with 16 cores each.
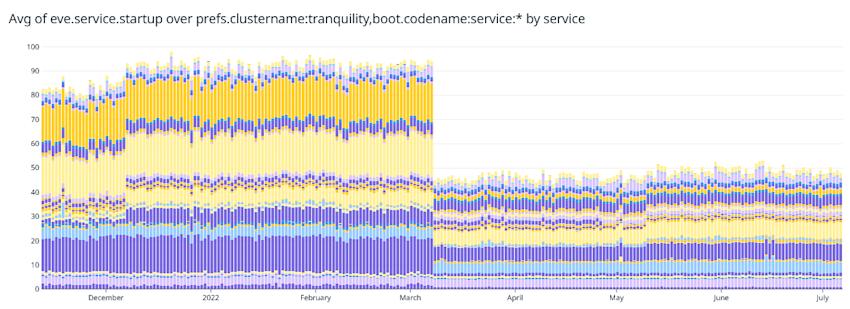
After moving to the new SAN, the new database hardware, and SQL Server 2019 in October 2021, it was time to look at the few remaining startup issues. These were eventually solved with software changes. During startups the average service startup time across all the nodes for each service did not tell the entire story, since the average was skewed by a few random nodes each time taking a long time. The head node in the cluster orchestrating the startup had to wait for the last node at each step, so the maximum service startup across the nodes is what mattered. This was traced to random slow responses from the database where lists of values were being converted to ordered tables that were unkeyed heaps. Instead, a set of conversions from lists of values to keyed tables were created and then a large set of stored procedures were tested to see which method worked better. The first batch of fixes was deployed in March 2022 and improved the startup significantly. The maximum was drastically reduced:

And that resulted in a better average:
Ranking up
The bulk of the machines in Tranquility; the so called ”Rank-and-File” E5-2637 v3 machines; would become seven years old at the end of 2022 and would leave extended warranty.
ℹ️ 'Rank-and-file' is how we refer to the largest group of machines in Tranquility that mostly handle solar system simulation. Tranquility isn’t a homogeneous cluster, neither from a hardware perspective nor a software perspective. Various services, such as the market, are on different hardware and loaded solar systems such as Jita are separate. In Tranquility Tech III Jita started off on a E5-2667 v3 machine, then later moved to a Gold 5122 machine, and then a Gold 5222 machine, all of which were not the rank-and-file machines of Tranquility Tech III. By contrast, currently Jita is on a Gold 6334 machine, which are the rank-and-file machines of Tranquility Tech IV.
So it was decided to buy fewer but larger machines to replace them. Tranquility is arranged in five FLEX chassis (with a 6th spare chassis).

Tranquility Tech III had five rank-and-file machines in each chassis, where each machine was a dual-CPU quad-core system (total of 8 cores) and ran 8 nodes (a total of 200 active nodes and 40 spare nodes). Each rank-and-file machine in Tranquility Tech IV is a dual-CPU octa-core system (total of 16 cores), and there are three of them in each chassis; each one runs 13 nodes at the moment (a total of 195 active nodes and 39 spare nodes), which we are likely to reduce because of improved performance. In short, 30 machines were replaced with 18 machines while keeping the node count similar.
ℹ️ A node is a PROXY or SOL process in the game cluster that is assigned specific tasks. For example in Tranquility Tech IV there are 170 nodes assigned to general solar system simulation for all Empire, Null, and Wormhole solar systems. But on the other end of the spectrum Jita is solo on one node and the market for The Forge is solo on another node.
The new machines are Lenovo ThinkSystem SN550 v2 dual-CPU machines with two octo-core Intel Xeon Gold 6334 3.60 GHz processors and 512 GB DDR4 memory at 3200 MHz.

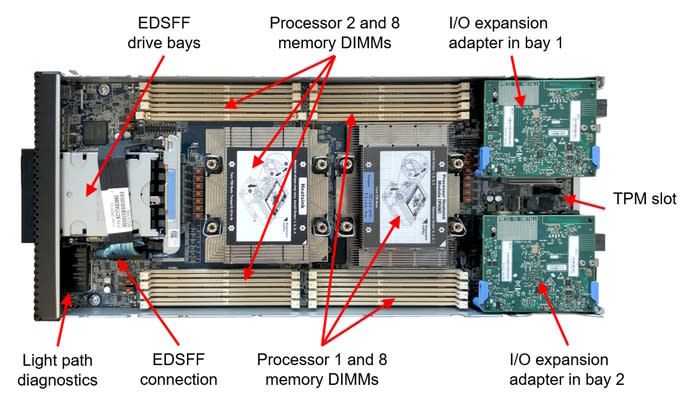
The CPUs are run fixed at their base frequency of 3.60 GHz since only half of the cores on each CPU can run as high-priority cores at 3.70 GHz, and then the other half drops to 3.40 GHz and we can’t control which node/solar system ends up on the high-priority cores and which on the low-priority cores. Variable frequency also interferes with our CPU usage metrics.
DDR4 RAM at 3200 MHz is a solid step up. This is the highest memory bus speed we have ever had; the previous rank-and-file machines' DDR3 memory ran at 2133 MHz (and the Gold 5122/5222’s DDR4 memory runs at 2666 and 2933 MHz); and the upgrade from DDR3 to DDR4 is a significant performance boost. In particular, the memory bus speed increase is important.
Since 13 nodes are run on each of the new machines, 512 GB total RAM entails an average of 39.4 GB per node. This is a step up from the 32 GB average on the old machines but is less than the 48 GB average on the Gold 5122/5222 machines. So we host memory-hungry nodes, such as all Character Services which are primarily Skills & Skill Training, and also all of Industry, on the Gold 5122/5222 machines.
A side-note here is that we run 40 Character Services nodes and so the total memory space for those services is close to 2 TB. We have found in our #nodowntime experiments that the memory pressure on those machines is about 75% at the end of day 2 or around 1½ TB of total allocated memory.
A side-note on the side-note is that in the that latest #nodowntime devblog, we noticed that “an auto reboot downtime of 3 minutes and 30-40 seconds is pretty normal these days“ – but in 2023, with all these improvements mentioned and more, it is 2 minutes and 5-15 seconds. Here's the very “scientific” #nodowntime progression graph from 2021 updated:

We also said back then that “there is a (soft) lower bound of approximately 3 minutes given the three different activities during downtime - shutdown, database jobs, startup - which last approximately 1 minute each, unless fundamental changes are made, and the most fundamental one is still to not have any downtime at all; downtime will not become much less than 160-200 seconds”. That was then - we're now at 125-135 seconds. Each of the three different activities during downtime has now been improved to approximately 43 seconds compared to the previous one minute.
The auto reboot is a very intense period where all systems are run at maximum throttle, so this gives a good indication of the performance boost of these recent changes and how the new CPUs and new RAM have verifiably improved Tranquility’s performance.
Another way to see that is to look at a stable group of nodes - the nodes simulating the Empire solar systems:
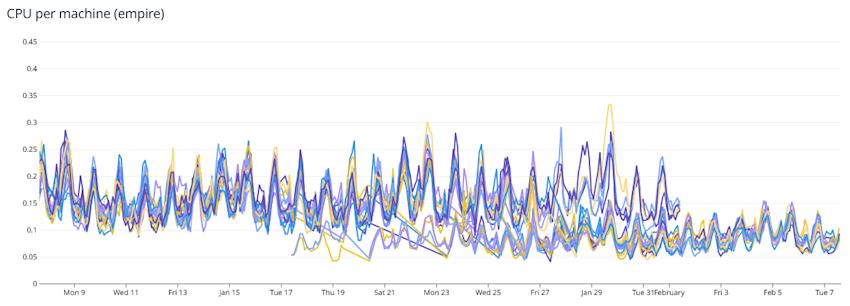
This graph shows the effect as the new Gold 6334 machines were swapped in and the old E5-2637 v3 machines were removed over a period of two weeks. This graph would also be indicative of the performance improvements in unexpected fleet fights.
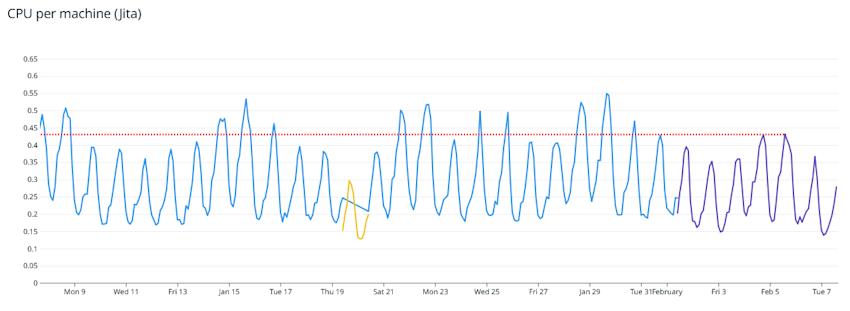
The effect is less when comparing Jita before and after, since Jita was on a Gold 5222 machine, but comparing weekend peaks there are still good performance gains:
The performance improvements in fleet fights for which we get Fleet Fight Notifications ahead of time will be comparable to Jita’s.
Finally, back on the hardware path after this detour into software and metrics, all the PROXY hardware was replaced, removing the old E5-2667 v3 machines and replacing them with new Gold 5315Y machines. This is more a refresh to stay within warranty than anything else and players should never really experience what these machines are doing.
This might seem like a long post, but it’s a brief overview of the changes that have happened since 2016. The truth is the improvements never stop, and by the time you read this the machines used for other databases than the game database will have been updated. But that, and more, will be for another time.
Head on over to the EVE Forums to continue the discussion.
Fly safe!
