Tranquility Tech III is ready for you!

Now that a week or so has passed since we lifted VIP mode for the first time in our new Data Center, we can call out OPS SUCCESS!
Even though it was a pretty rough start on that eventful Monday, February 29th we are damn proud of this achievement.
I am going to take you through the days coming up to the move and tell you how things went in an honest and raw write up of the events.
The Task
Without a doubt, Tranquility Tech III (upgrading and moving EVE Online’s main game server) is the single biggest assignment the CCP Operations Department has taken on. It involved one year of planning, debating best approaches, tons of paperwork, complicated transfer logistics, and then finally moving safely between sites.
We took a good look at the current Tranquility Server (TQ) setup and there were a few low hanging fruits and some very big opportunities for updates.
The goals we set out for TQ Tech III were to improve:
- Reliability and stability of the hardware
- Performance across the entire cluster
- Network connectivity
- Simplicity of our footprint by moving TEST servers to Iceland
With all that in mind, and knowing that our current contract was coming to an end on the last day of March, we set the goal to be live on the 29th of February, AKA leap day.
Let’s start a few days before the big move to get the whole story.
Wednesday, February 17th – “Everest” Node Blue Screened
After years of dedicated, solid service, the “Everest” node which was responsible for the main trade hub in the game, Jita, blue screened, and market and player activity was moved over to a less powerful node
I just wanted to mention this event as the node had done so well for us and literally had 12 more days to go. Thankfully it recovered with a reboot and went back into action at next downtime and finished its tour of duty.
Wednesday, February 24th – Upgrading OS and SQL
On Wednesday 24th of February we had an extended downtime to upgrade current TQ databases to Windows 2012 R2 Operating system and SQL 2014. For the details here is CCP DeNormalized with a little backstory…
What has 5 members, lives in 2 buildings and spans oceans and continents?
The EVE Online Database cluster
So during the extended downtime we took a huge step towards our upcoming data center move.
One of the main issues we had to overcome was how to get the 2.5 TB database from one data center to the other with minimal downtime. Also, in addition to the move we need to upgrade both the OS and SQL version (from Windows 2008 R2 to Windows 2012 R2 and SQL 2012 Enterprise to SQL 2014 Enterprise).
Of these two issues, upgrading to SQL 2014 is the biggest concern. Or rather, not so much the upgrade, but the fallback plan in case we have to revert. You see, once you upgrade a DB from an older version of SQL you cannot move that database back to an earlier version. The only way is a DB restore from the same (or earlier) version.
So we decided that the least risk would be to upgrade the TQ DB servers to Win2012/SQL2014 while still in our existing DC. This meant that on the big move day we had so much less to worry about and we have an extremely familiar environment to work within in-case something went wrong.
In addition to this, we identified our preferred method of getting the DB to the new Datacenter – SQL AlwaysOn replication. We could not do this before as the machines have to be in the same Windows Cluster/same OS versions.
So the plan was to merge two separate two-node SQL failover instances into one Windows Cluster and use AlwaysOn to keep the data in sync. This would give us the ability to fail back from the new DC to the old one if we wanted (which we don’t, but we could!!)!
Part of what took us so long was that we added a pretty amazing (or so we think) test step into the mix…
We started by evicting the passive node of our production DB cluster, re-imaging it with latest OS, and joining it to our existing Windows Cluster in the new Datacenter to create a new single node SQL Cluster. Lots of stuff involved here in getting a Windows Cluster to span two datacenters--much thanks to the SysAdmin and Network guys!!
Just as a note, running with no failover partner isn’t something we like to do, but it was necessary and would be for less than 24 hours.
So at 09:00 GMT we shut down everything and continued! We did things like move the SQL Cluster IP from the ‘old’ cluster to the new single node cluster and copied the smaller DB’s to the new disks. For the large DB’s just remapped SAN volumes and reattached the databases.
But this brings us to the DB upgrade step. If we attached the SQL 2012 DB to our new SQL 2014 instance it would run an internal upgrade, at which point it would become incompatible with all previous SQL versions. If something didn’t work for whatever reason, we would have had no choice but to do a restore of the backups we took earlier in the morning. We would not be able to simply move the volumes back to the old cluster (which was still running, just as a single node as our fallback)
Enter brilliant idea – prior to presenting the SQL 2012 volumes to the new 2014 Cluster we would take a SAN snapshot of those volumes. We give the snapshot volumes to the new cluster, attach the databases from the snapshot disks, and let the upgrade happen. We started in VIP to check out some stuff. Things looked good so we removed those DB’s – unmapped the snapshots, destroyed the snapshots, and gave the cluster the ‘real’ disks and did it all again after a reboot.
It took time which contributed to missing the initial target time, but we felt it was worth it!
We added disks to the cluster, setup mount points, attached databases, started Tranquility in VIP mode again. Woohoo, everything looked great so we opened the gates!
Shortly after opening, we went back to the old cluster and stole its now lonely node. This was added back into the new cluster and we’re redundant again!
For the most part everything went smoothly… We did have several issues with bringing disks online and it meant a reboot or two (each reboot is 15 minutes). This cost us the over-extension but we are very pleased with getting to this stage.
- CCP DeNormalized
Friday, February 26th – Unexpected Database Downtime
At this stage we were preparing to go live and things looked good with AlwaysOn capabilities in place and old TQ stable after the DB upgrade, which we had expected after multiple prior upgrades.
Confidence was high but at around 19:50 GMT we started seeing errors in our SQL log backups with so-called dirty pages accumulating in memory of the SQL server.
After a quick look we decided to take down TQ at 20:15 GMT to prevent loss of data vs. trying a live fix. So now that the server was down we could investigate properly and collaborated with Microsoft Premier Support.
We started a “Severity A” call with them and about 30 min later we had a senior SQL engineer on Skype in a screen share session which proved to be really fast debugging situation vs slow email / phone debugging.
After a little while we heard him say “Ahh it’s EVE! I should get back into EVE!”--great to know a capsuleer was on the other line!
He had a pretty cool method to safely flush these dirty pages from RAM to Disk so we could essentially get them backed up--basically reducing the allocated RAM in small increments to make the dirty pages decline slowly and allow backups to continue.
Then to be absolutely sure, we wanted to make one full backup of TQ while TQ was still in VIP so it took quite some time, pushing VIP-mode lift to 23:50.
The root cause was hinted to be around old replication features which should not have affected anything, but as it is so often in the IT business unexpected things pop up.
Once we had the issue under control and our dirty pages in order, we had an intensive discussion back and forth on how best to proceed. Least risk won out and we decided to do the actual move using traditional backup and restore.
Monday, February 29th - Leap Day – The Move
Since we had opted away from SQL AlwaysON, we adjusted our timeline predictions and we were confident to make the 14:00 GMT mark.
Everyone was in and ready for action at 08:00 GMT.
Following the final GO (as opposed to NO GO), the atmosphere was electric and huge excitement for the day to come. At 09:00 TQ went down for the last time in its old home.
Then we progressed through the services needed, feeling good about our timeline as we approached the 10:30 marker. We started TQ for the first time ran a couple of checks and took TQ then back down.
At 11:00 we started a full stack EVE server, meaning it had all the auxiliary services like SSO, VGS, API, etc. followed by various QA tests from the development teams
Lots of small issues were discovered and fixed on the fly, like an emergency room where we had sudden influx of patients and the OPS team and EVE Developers just operated on them by severity and one by one we got to the point where every service was in a functional state.
The schedule was getting tight at this point, but it was clear that we did not want any quick workarounds. We wanted to do things right and if needed we would just extend the downtime.
Which we eventually had to do at 13:30, requesting an hour.
Shortly after that announcement things actually came together and at 14:20 GMT we started TQ in VIP with one last round of checks just to be 100% sure and then finally at 14:27 GMT we lifted VIP and it was a glorious moment when we saw the flood of players coming in…
..and then we got quickly pulled back to earth from our celebration when the Launcher showed almost an immediate stress signal and the web sites also went really high in utilization. After a while things calmed down and logins started flow correctly then the big bang came. Not the good kind.
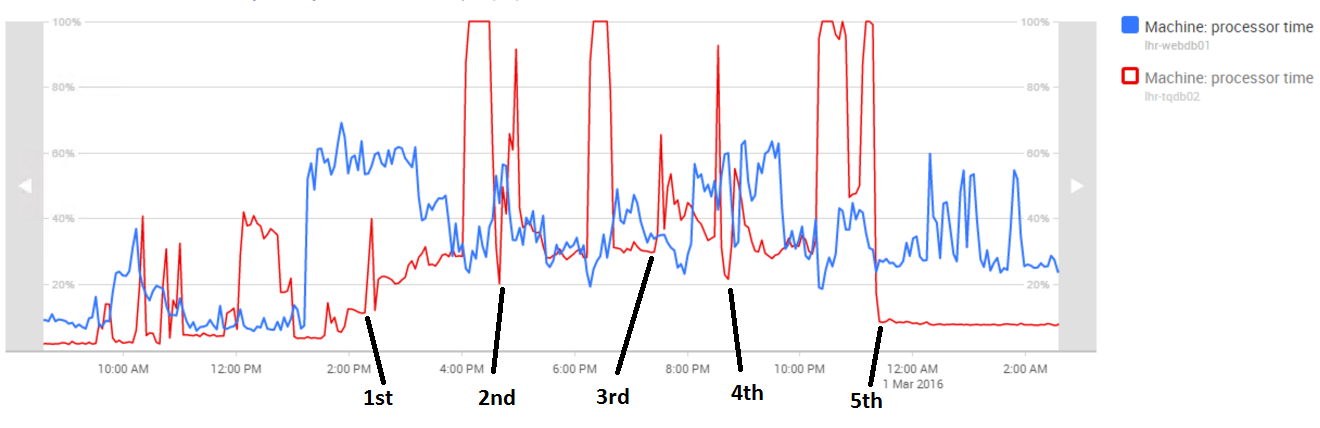
BOOM TQ Database CPU went up to 100% without any warning or any indication that load was increasing, almost instant jump so what follows now is the tale of five startups:
(click to enlarge)
1. This is where we thought everything was fine and man we were happy
- About 90 minutes into the run we hit the 100% CPU and it was diagnosed as a stored procedure which hits a bad query plan.
- We had seen this happen on TQ before but it’s ultra-rare so we pinned this as a once in a blue moon, and such bad luck it hit us on this day. We went on and took down TQ and started up again.
2. Second run we were scared it would hit us again, so we pulled back a little bit on the celebration.
- Again the launcher and websites did not like the influx of players, but as time passed that calmed down like before
- Again roughly 90min into the run this same symptom hit us again though a different set of stored procedures. Another bad query plan taking down the server with up to date indexes that should not be happening
- We raised a code red and called all hands on deck and EVE Development came up with a proposed fix to the stored procedure problem, but they agreed with the Database team that this just didn’t make any sense
- We went on and took down the server applied the hot fix.
3. Shortly after the third startup we saw that the market was not loading correctly and more errors were raised very shortly after the startup--mostly the result of us trying to get the server up and running to fast. Took it down for more preflight checks.
4. Now we are somewhat into the night and we see social media both understandably raging and opposing positive posts which which boosted morale … Thank you ;)
- This is where we still confident that the hotfix would get us through
- Here we also found performance draining setting related to the launcher and websites and we also pushed more resources to the web front end machines as we did not have these type of “sudden influx” problems
- We watched a countdown timer set to 90 min as that was our longest run. I can’t describe the feeling when we hit 90 minute mark … and it blew for the third time with 100% CPU on the Database.
- Since the proposed fix and other measures we did were not working we shortly entertained the idea of fallback but opted first to failover the SQL cluster to a passive node and changed settings with RAM allocation
- Had to Shut down yet again and things were becoming very unsettling to say the least.
5. Fifth Time’s The Charm
- We reset our 90 minute counter and thanks to CCP Seagull who showed up shortly after mid-night with much more Red Bull and treats :)
- The waiting game now was getting very intense and next steps were going to be hard if we had to go into a roll back scenario
- At 23:47 we were ready for the fifth startup and lifted VIP
- We split up the team and some went home to be ready day after others went to sleep in meeting rooms to take shifts throughout the night
- Then we watched as the counter went to 80 min …. 85 …. 88 ..... 90……… 91 …………….….92 and then time passed and we hit our 2 hour goal and 2.5 hour goal and finally at 3 hours of run time we felt we were in the clear!
TQ ran smoothly that night, and within Operations we had set a goal when this whole project started to go live on the 29th and since the fifth startup lifted VIP before midnight we still claim we hit our high level plan.
Sadly, promptly at 09:00 GMT March 1st TQ took itself down which was due to one of couple of automatic downtime settings which were forgotten to set back to its regular 11:00 GMT setting. Just plain and simple human error at fault.
This was how that eventful Monday played through and I can tell you that going through a project of this magnitude over such a long time is extremely hard but also extremely gratifying when you see the fruit of your collective labor.
TQ Tech III Thusfar
A few days have now passed, and we already have had one brawl in Hakonen where 1500 pilots fought, which ran on one of the 25 “standard nodes” of TQ Tech III. The 6 reinforced nodes of TQ Tech III still remain to see proper action so we wait eagerly to see how they perform
We saw reports of both good positive and negative feedback which obviously helps us tweak and fine tune the hardware.
To illustrate the improvements here are graphs of wisdom from CCP Quant!
Performance Changes
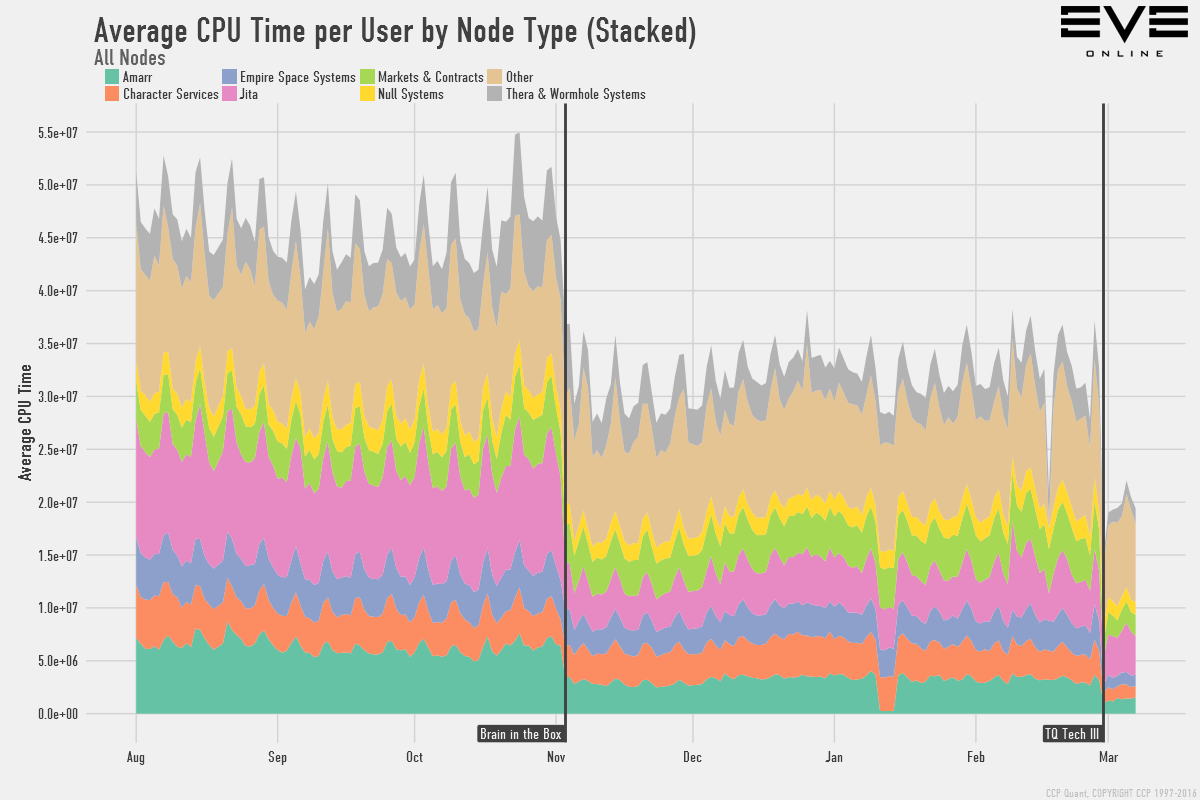
Tech III combined with "Brain in a box"(BiaB) have dramatically improved EVE Server performance, but by how much exactly? To give you some sense of scale here and how these changes are likely to affect your gameplay, here are a few graphs to show how load has changed:
(click to enlarge)
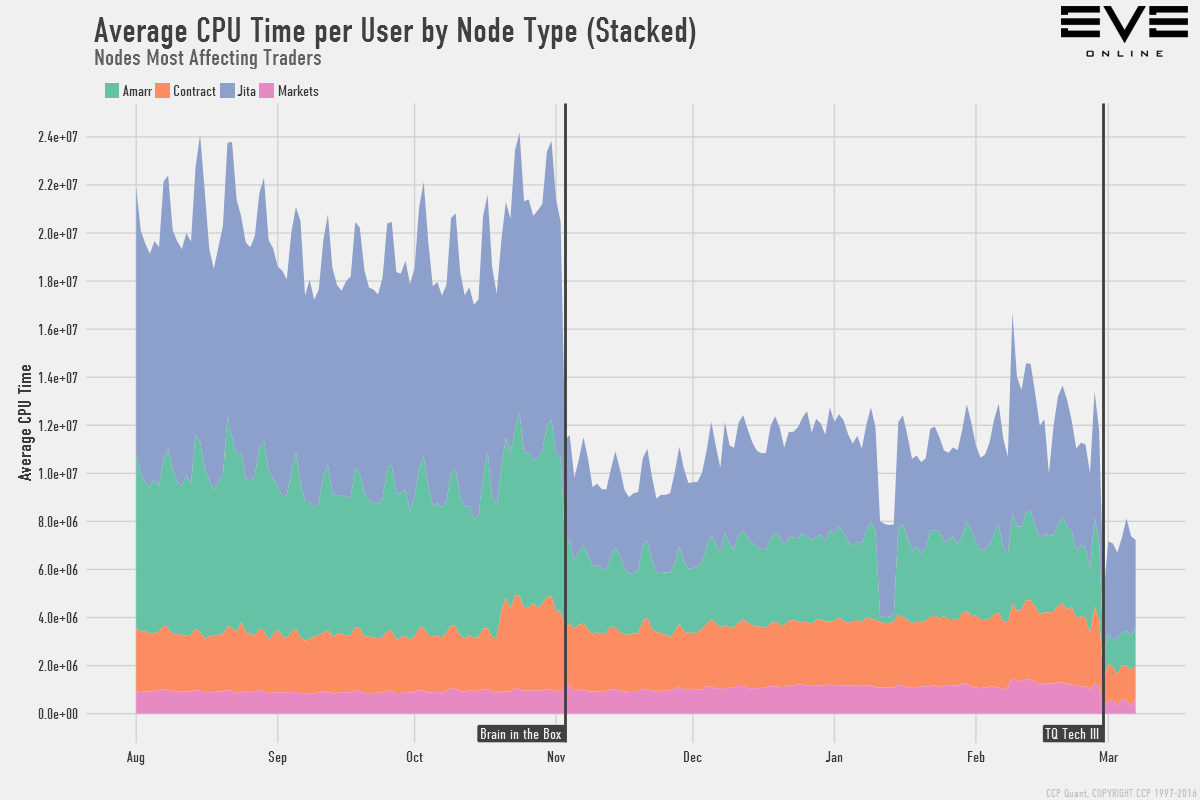
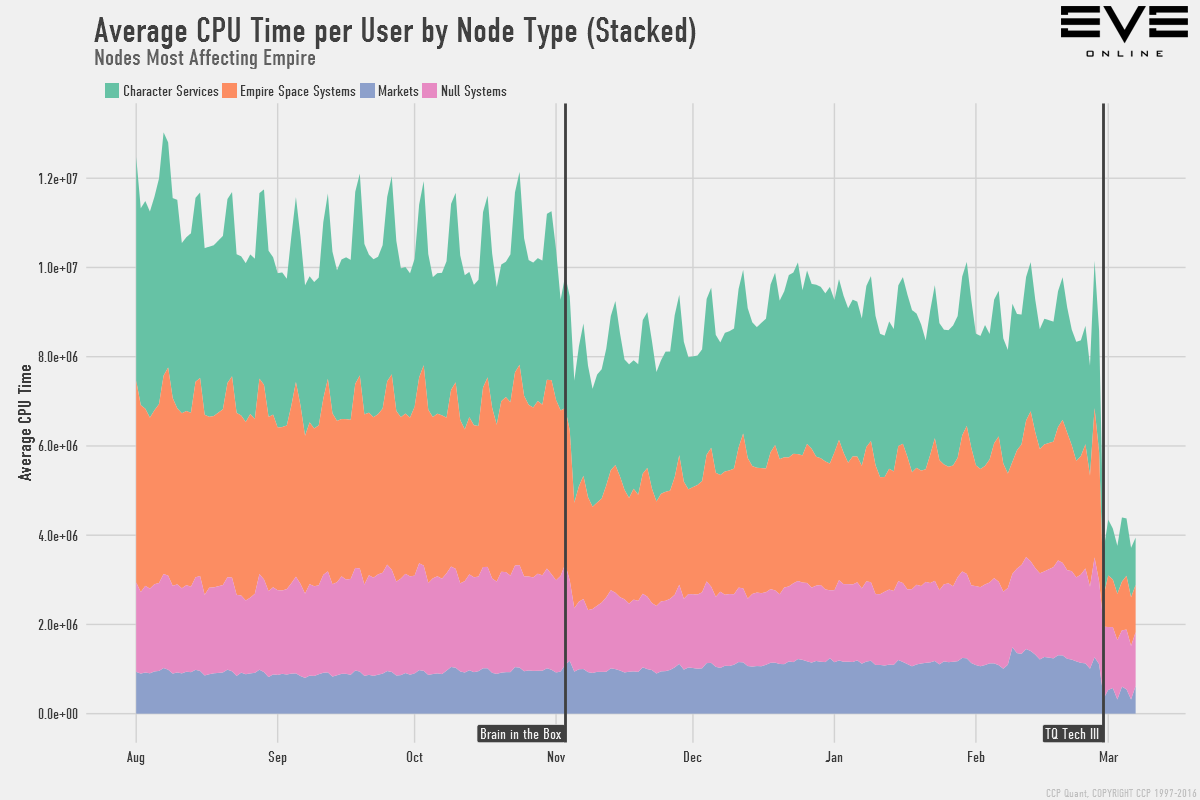
This shows how the overall average CPU time per user by node type. Don't read too much into the numbers themselves, they are rather abstract and are there to provide a scale for reference. The average CPU time per user now is about 40% of what it was back before we launched BIAB. Following are subsets of this graph depending on gameplay around Empire Space, Wormholes, and Trading to take a few examples:
(click to enlarge)

(click to enlarge)
(click to enlarge)
To read into the last one, you can see how much more responsive you can expect markets to be in Jita for example. The changes not only improve overall responsiveness but also make large fleet fights more viable.
Here is a very interesting graph showing CPU load and Time Dilation (TiDi) on the node that Hakonen was mapped to during the big fleet fight on Mar 2:
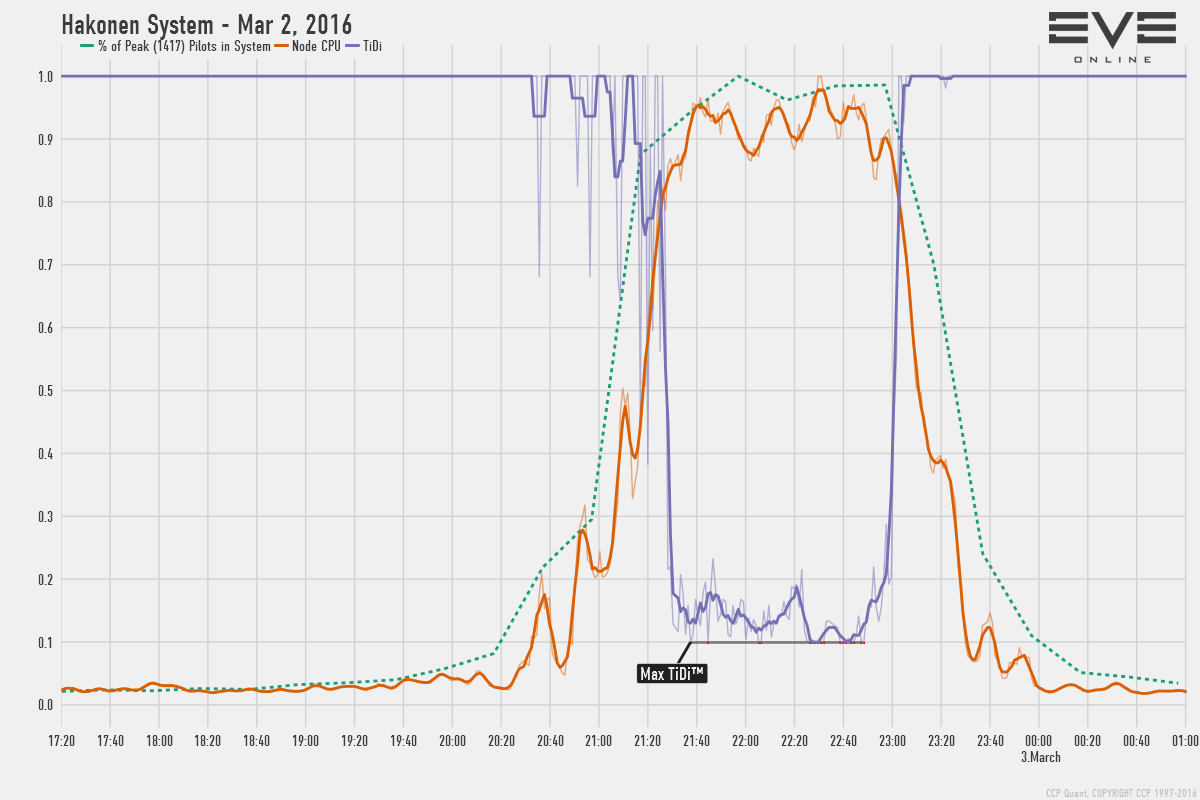
(click to enlarge)
The system was not on a reinforced node, and it is in low security space, meaning that a lot of extra calculations are needed on the node for the crime watch system, i.e. keeping track of aggressors, standings, gate guns, etc. Time Dilation can't go below 10% and if it stays at 10% the task queues start filling up and players will experience things like modules not cycling, etc. eventually leading to node deaths. Looking at this graph we can see that TiDi went all the way down to 10% a few times, but the only periods of it staying there only span about 2x ~5 minutes. This means that those of you who did experience issues outside of dilated time, most likely did so during these periods. While TiDi stays above 10% it means the node is successfully processing the task queues with help from the time dilation and here we can see that rather than flat lining at 10%, it managed to stay between 10-20% during the peak of the battle.
- CCP Quant
More on the future
Now that’s impressive on the server performance but we are not in any way done additionally looking forward with our new network setup we are very much focused on network latency and reliability.
Specifically we’re using the automated BGP network solution we ran as a proof of concept while TQ was in its old home, which actively looked for better routes in order to re-route connections through the interwebs if "the box" finds a better path for you. This all happens without socket closure of course.
Tests came in with excellent results. For example we decided to drop one of our Internet Service Provider and contracted another one instead.
Basically if the ISP's are not good enough for EVE players, we drop them and sign someone who has proven to be better and is up for the challenge. This automated BGP solution will go in full production any day now stay tuned for follow up blogs.
Related to that, we have much more powerful edge routers. Here is a message from one of our network wizards
"The EDGE Router in the new data center is now receiving a total of 2.9 million BGP routes from 23 peers. The highest CPU utilization when calculating the best-path BGP table and backup route tables on this new router has been 8% CPU, while using the old router in Telecity, any BGP table recalculation would take the router to 100% CPU. That is quite an improvement in performance!"
We now have our eyes glued to the instruments to see what’s running hot. With the flexibility of TQ Tech III we are in a lot of control to balance load, which is great considering the Citadel expansion is right around the corner with all those capital ship improvements and new structure capture and defend mechanics...
We will start tweaking even further and constantly target pain points to improve your experience flying in New Eden.
On behalf of the operations team I proudly and officially welcome you to TQ Tech III
- CCP Gun Show
