CarbonIO and BlueNet: Next Level Network Technology
Most folks familiar with EVE know that it's built on Python, Stackless Python to be specific. Stackless is a micro-threading framework built on top of Python allowing for millions of threads to be live, without a lot of additional cost from just being Python. It is still Python and that means dealing with the Global Interpreter Lock (hereafter known as the damn stinkin' GIL, or just GIL for short).
The GIL is a serial lock that makes sure only a single thread of execution can access the Python interpreter (and all of its data) at a time. So as much as Stackless Python feels like a multi-threaded implementation, with the trappings of task separation, channels, schedulers, shared memory and such, it can only run a single task at any given time. This is not unlike some of the co-operative multitasking operating systems of the past, there is power in this model as the framework makes the promise to all executing threads that they will not be preemptively ended by the system (apart from when the system is suspecting the micro thread to be in violation of the Halting problem). This allows game logic code to make a lot of assumptions on global program state, saving a lot of complexities which would be involved in writing the acres of game logic that make up EVE Online to be written in a callback driven asynchronous manner. In fact most of the high level logic in CCP products looks naively procedurally synchronous, which helps a lot with the speed of development and maintainability for the code.
The down side of all of this is that some of the framework code in EVE Online is written in Python and is thus victim to the GIL. This includes any C-level module that wants to access Python data, the GIL must be acquired before it so much as looks at a string
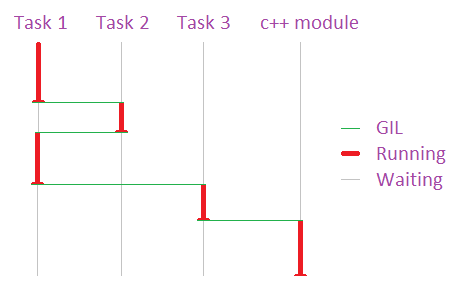
All tasks working within Python must acquire the singular GIL to legally process, effectively limiting all Python to a single thread of execution.
(please excuse the primitive graph, I'm a programmer not an artist)
Bottom line: Code written in Stackless Python can only execute as fast as your fastest CPU core can go. A 4 or 8 CPU big-iron server will burn up a single CPU and leave the others idle, unless we span more nodes to harness the other CPUs, which works well for a lot of the logic in EVE which is stateless or only mildly reliant on shared state but presents challenges in logic which is heavily reliant on shared state, such as space simulation and walking around space stations.
This is not a problem as long as a single CPU can handle your load, and for sane uses of Python this is true. I shouldn't have to tell you that we are hitting the point at which a single CPU can't process a large fleet fight, despite the work of teams like Gridlock in squeezing out every drop of optimization that they can. CPUs are not getting any faster. They are getting more cache, fatter busses and better pipelines, but not really any faster at doing what EVE needs done. The way of the near (and perhaps far) future is to 'go wide' and run on multiple CPUs simultaneously.
Overall the proliferation of multi-core CPUs is good in the long term for EVE, the basic clustering method that EVE uses will work really well for computers with more than 30-60 cores, as then the routing between cores eclipses the benefit of having the threads of a process flow between the cores but right now we are in the spot where the framework parts of EVE, such as networking and general IO could benefit a lot from being liberated from the GIL.
Multi-core superscalar hardware is good news for modern MMOs, they are well-suited to this paradigm and trivially parallelizable, but not-so-good news for Python-dependent EVE. It's not news: now more than ever, performance critical EVE systems which do not need the benefits of rapid development and iteration in Python need to decouple themselves from the GIL, and soon. CarbonIO is a giant leap in that direction.
CarbonIO is the natural evolution of StacklessIO. Under the hood, it is a completely new engine, written from scratch with one overriding goal tattooed on its forehead: marshal network traffic off the GIL and allow any c++ code to do the same. That second part is the big deal, and it took the better part of a year to make it happen.
Backing up for just one minute, StacklessIO (//www.eveonline.com/devblog.asp?a=blog&bid=584) was a quantum leap forward for Stackless Python networking. By making network operations "Stackless aware" a blocking operation is offloaded to a non-GIL-locked thread which can complete its wait while Stackless continues processing, and then re-acquires the GIL, notifying Stackless that the operation has completed. This lets the receive run in parallel, allowing communications to flow at OS-level speeds and be fed as-needed into Python as fast as they can be consumed.
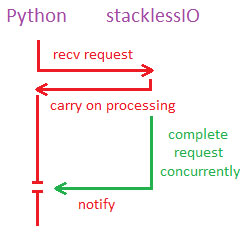
stacklessIO completes Python requests without holding the GIL
CarbonIO takes that a step further. By running a multi-threaded communications engine entirely outside the GIL, the interactivity between Python and the system is decoupled completely. It can send and receive without Python asking it to.
That bears repeating: CarbonIO can send and receive data without Python asking it to. Concurrently. Without the GIL.
When a connection is established through CarbonIO a WSARecv() call is immediately issued and data begins to accumulate. That data is decrypted, uncompressed, and parsed into packets by a pool of threads that operate concurrently to any Python processing. These packets are then queued up and wait for Python to ask for them.
When Python decides it wants a packet, it calls down to CarbonIO, which probably already has the data ready. That means data is popped off the queue and returned without ever yielding the GIL. It's effectively instant, or at least nano-secondly fast. That's the first big gain of CarbonIO, its ability to do parallel read-ahead.
The second big gain is on sends. Data is queued to a worker thread in its raw form, and then Python is sent on its way. The compression, encryption, packetization and actual WSASend() call all occur off the GIL in another thread, which allows the OS to schedule it concurrently on another CPU. A method is provided to allow c++ code to do the same, but that requires no special architectural overhaul, StacklessIO could have done that too, but without the whole picture it would have been pointless.
Now back up a minute. "Already has the data ready". Hmm. What if we were to install a c++ callback hook that allowed a non-Python module to get that data without ever touching Machonet? Welcome to BlueNet.

CarbonIO runs its recv-loop continuously, and can notify a c++ module of data arriving without Python intervention.
Machonet is a large collection of functionality which marshals, routes, manages sessions, handles packet scheduling/delivery and all the other glue that holds EVE together. It is a Python module, so all data must pass through the cursed GIL at some point, on every EVE node. No matter how fast a c++ module is for EVE, it is still beholden to that bottleneck. This discourages a lot of potential c++ optimizations, since any gain would be chewed up acquiring the GIL and thunking into Machonet.
But not anymore.
Now a c++ system can receive and send packets through BlueNet and never care about or need to acquire the GIL. This was originally coded for Incarna, which needs to send a significantly higher volume of movement packets to support a walk-around MMO. In space you can cheat, but not so with close-up anthropomorphic motion. Early projections showed that even with a modest tick-rate, Incarna would bring the Tranquility cluster to its knees. BlueNet solves that problem by routing traffic in parallel with the GIL, to and from c++-native systems (like Physics). This is faster because the data stays in its native, bare-metal form and not double-thunked for every operation, a huge savings.
How does this work? BlueNetmaintains a read-only copy of all necessary Machonet structures, in addition to this a very small (8-10 byte) out-of-band header is prepended to all packets. This header contains routing information. When a packet arrives, BlueNet can inspect this out-of-band data and sensibly route it, either by forwarding it to another node or delivering it to a registered c++ application locally. If it forwards it, this happens in-place off the GIL; Machonet/Python is never invoked. This means our Proxies can route BlueNet packets entirely in parallel, and without the overhead of thunking to Python or de-pickling/re-pickling the data. How effective is this? We're not sure yet, but its somewhere between "unbelievably stunning" and "impossibly amazing" reductions in lag and machine load for systems where this is applicable. Seriously we can't publish findings yet, we don't believe them.
In addition CarbonIO has a large number of ground-up optimizations, mostly small gains that add up to faster overall code, a few worth mentioning:
Work Grouping
It is difficult to be specific, but CarbonIO goes out of its way to "group" work together for processing. In a nutshell, certain operations have a fixed transactional overhead associated with them. Network engines have this in spades, but it applies to all significant programming, really. Through some pretty careful trickery and special kind of cheating it's possible to group a lot of this work together so many operations can be performed while paying the overhead only once. Like grouping logical packets together to be sent out in a single TCP/IP MTU (which EVE has always done). CarbonIO takes this idea several orders deeper. An easy example would be GIL acquisition aggregation.
The first thread to try and acquire the GIL establishes a queue, so that any other threads trying to acquire it simply add their wake-up call to the end of the queue and go back to the pool. When the GIL finally does yield, the first thread drains the entire queue, without releasing/re-acquiring the GIL for each and every IO wakeup. On a busy server this happens a lot, and has been a pretty big win.
openSSL integration
CarbonIO implements SSL with openSSL and can engage this protocol without locking the GIL. The library is used only as a BIO pair, all the data routing is handled by CarbonIO using completion ports. This will allow us to take continued steps by making EVE more and more secure and even allows for some of the account management features of the web site to be moved over to the EVE client for convenience
Compression integration
CarbonIO can compress/decompress with zlib or snappy on a per-packet basis, again, independent of the GIL
Field Trials
Data collected over a 24-hour run of a busy proxy server (~1600 peak users, a typical week day) Showed the overall CPU% usage drop dramatically, as well as the per-user CPU%. This reflects gains from the overall paradigm of CarbonIO, which is to reduce transactional overhead. As the server becomes busy, the effectiveness of these optimizations begins to be dominated by the sheer number of transactions that must be performed, but at peak load it still showed a substantial gain.
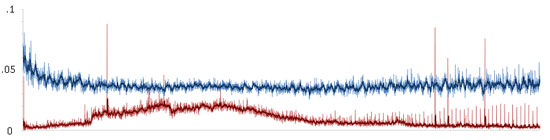
CPU% per user over a 24-hour run
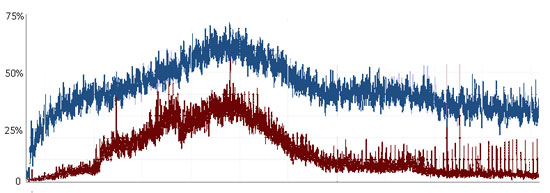 Raw CPU% used over the same 24-hour period
Raw CPU% used over the same 24-hour period
Sol nodes benefit much less from these modifications since their main job is game mechanics rather than network activity, but we still saw measurable improvement in the 8%-10% range.
It is important to note that none of the BlueNet options were engaged with these trials, no c-routing, no off-GIL compression/encryption. These were meant to be in-place process-alike tests which were fearlessly attempted on live loads to ‘proof' the code once we had thrashed it as much as we could in closed testing. The gains we see here are gravy compared to the performance gains we will see on modules that will use the new functionality.
Bottom Line
What this all means is that the EVE server is now better positioned to take advantage of modern server hardware, keeping it busier and doing more work, which in turn pushes the upper limit on single-system activity. By moving as much code away from the GIL as possible, it leaves more room for the code that must use it. In addition, since less code is competing for the GIL, the overall system efficiency goes up. With the addition of BlueNet and some very optimal code paths, the door is now open. How far it swings and what gains we end up getting remains to be seen, but at the very least we can say a major bottleneck has been removed.
