Fixing Lag: Fostering meaningful human interaction, through testing and communication.
Howdy folks,
As CCP Zulu mentioned in his recent blog, we want to shed more light on the work that has been done to combat lag and generally improve the performance of EVE. I'll be focusing on the QA end of things, especially about our mass-testing program and the work we've been doing. All told, we've gotten quite a few improvements out to EVE through the pipeline, made several adjustments to the mass-testing program, gathered a ton of logs and data, made some good progress on the fight against "lag," and began working directly with the CSM to build an action plan for the future. All this is pretty good stuff, and we're very excited to finally be able to share it with you all.
What is mass-testing, anyway?
Mass-testing is a program we've been running for a while now that brings developers and players together, on the test server, to hammer away at various new changes and features while involving players directly in how we assess the quality of EVE. At its core, the Mass-Testing program does three things: allows us to gather performance trend-data for EVE; allows us to more rapidly get high-priority changes tested by a large number of EVE players; and allows us to get critical feedback about new features/changes to EVE, before we release them to Tranquility (or "TQ," EVE's production server). It is important to note that mass-testing is not just to investigate "lag," but is really a framework to get vital changes tested and, most importantly, quickly get feedback from EVE players about those changes. Additionally, it also allows us to get performance trend-data from each new major build.
This all comes together to give CCP's teams, producers and managers a much better picture of where we stand and where we need to focus our attention to make things better. This is especially true when it comes to player feedback. It can be said that "perception is reality" and if that's considered to be true, then what EVE players think of the quality of the game is a truly vital indicator about the overall quality of EVE that we cannot ignore. We've taken this idea to heart, in several ways, and will endeavor to use mass-testing to retain an open dialog between CCP's developers and the EVE playerbase, especially through the CSM.
What've we been up to with mass-testing, all this time?
That's a very valid question that we've been seeing often. We've been running test after test for many months without really talking much about what's going on behind the scenes, and we've realized that that isn't the best way to go about things. So, without further ado, I'll give you all a short summary of what we've done via the mass-testing program over the last several tests or so, and what that has provided for EVE.
- In mid-February, I published a dev blog announcing the start of the 2nd iteration of the mass-testing program
o The first in this series of tests was on February 20th
o We try to run a mass-test event at least every two weeks
o A brief summary of the results of this test, and all subsequent ones, can be found here.
-
The primary issues we were testing during this time have been the "long-load" issue, or "jumping lag" issue, overview misbehavior, and module activation issues. All of these can be lumped into the general "lag" category.
-
In addition to "lag" testing, we also ran tests of the Planetary Interaction feature, and the new EVE Gate website.
-
As a result of this testing, we've been able to make several fixes and adjusted things about features, based on your feedback. Some, but not all of these changes are:
- Server-side changes to how we handle session changes - making them behave better
- Improvement to module cycling - changed how the server processes these types of calls
- Fixes to the overview to make it update more appropriately
- Improvements to the Planetary Interaction UI, making it easier to use
- Changes to EVE Gate, making it a bit more user-friendly
- Server-side fixes for module cycling, making it less likely to ‘bug out' during high load situations
- Internal data-gathering improvements (better data = faster fixes)
- There's more, a lot more, but I'll let the awesome programmers talk more about those, in later blogs
This may also beg the question: "why haven't we seen any blogs about this until now?!" That's a much trickier question to answer, but the long and the short of it is: we were, and still are, in the middle of our investigations. We realize that that answer isn't the greatest, but it's the truth. Quite simply, it's difficult to talk about things while you're in the middle of working on them. That being said, we're not happy with the lack of communication either, and we've been taking steps to improve things on our end and will continue to do so until we're happy with it. This blog is just part of that process. We will also be working with the CSM to ensure communication between the folks working on these issues and the players continues to flow, and that we're at least addressing the big questions on player's minds.
What does mass-testing really show us?
Those of you who have been to mass-test events in the past probably have heard, "we're getting lots of good data!" What exactly have we gathered? I'll give you a glimpse into the data analysis we do, with examples from the latest mass-test.
Let's start out by defining what we were looking at: Module activation andcycling during fleet fights. Specifically, we had a new server-side flag that, when toggled, changes how the server handles the calls made by the EVE client when you activate and cycle your modules. CCP Veritas will have another blog going into much greater detail on this particular issue and fix, so I won't go into it much here.
So, the test:
We had three fleets total, which first jumped en-masse between two pre-defined systems (MHC and F67), in order to generate a baseline for server performance. This was then repeated with one fleet camping the final system, and the other two fleets jumping into them and engaging (Poitot and X-BV98). This was done without the new server-side flag turned on. This gave us a good baseline of how things performed in a high-load situation which involved jumping, combat, and multiple fleets all at once. We then stopped combat, turned on the new server flag, and had everyone duke it out at a planet, with two fleets warping into the third, who was ‘defending.' This was then repeated one more time, initially without drones, to further isolate the changes being tested and determine how effective the changes were.
The results:
I'll start by showing you the server performance graphs from that test:
Note: Not all of the log-markers are placed exactly (ie. where it says "jump 1 start" etc). Unfortuantely, lag during the test caused the log-inserts to be delayed in some cases. Even we get pwned by the ebil lag sometimes :)
Looking at this first chart, we see how the server handled the first jump, and the exit portion of the second jump. You can see the node building up in resource usage as everyone enters the first test-system and then it spikes, very noticeably, when everyone jumps between the two systems. You can immediately see, from the timestamps alone, that the node was hurting and the jump took several minutes to complete for approximately 550 pilots involved. This is our first indicator for where to look for bottlenecks and where we could benefit from improvements. More on that later.
(MHC-R3, F67E-Q, and Poitot)
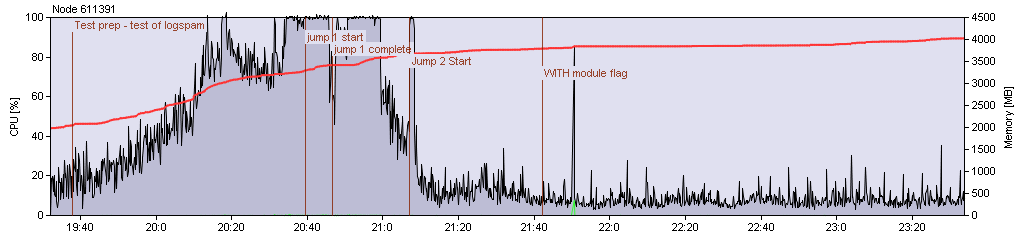
Now let's look at the really interesting graph, from the node where all the combat took place, X-BV98. Here we see the same "background noise" from everyone getting into position and whatnot, this is always to be expected and should effectively be ignored for the purposes of performance analysis. Anyway, we see again a long spike of maxed out resources on this node, though we must also account for the fact that this test added combat into the mix, not just jumping. The extra load is expected, but it also serves as a baseline for the latercombat tests where we will activate the new module-cycling flag on the server.
On the chart, the three big spikes in CPU usage coincide exactly with the three rounds of combat that took place (I said there'd be five, but we ran long and had to cut two rounds). After setting the baseline for "combat lag" for that test, we then proceeded to a planet to duke it out again, this time with the new server flag turned on. You'll also notice a spike in memory usage on the node, roughly at the same time. It was here that we still saw some fairly epic lag, but the important thing to note is that modules appeared to by cycling much more often than before. This doesn't mean there wasn't lag, and we must note that module activation/de-activation is a different type of call than modules cycling (ie. Repeating). This was made most evident by the fact that drones were still cycling in and doing damage and modules did far less "single shot" cycles, when on auto-repeat. We did find, however, that module activation and de-activation was unchanged from the previous test. The net result is a module that still takes a while to realize it's been turned on, but once it does, it should cycle more-or-less properly after that. This is further supported when you look at the tasklet data from that portion of the test, compared to previous runs. But I'll let CCP Veritas get into that in more detail in his upcoming blog.
(X-BV98, combat system)
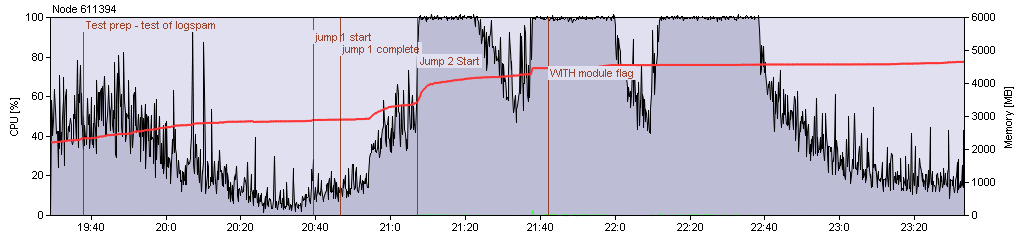
We then repeated the combat at the planet one more time, this time without drones, at first. In this test we saw far less "lag" due to the lack of drones. This allowed us to confirm our results from the previous round of combat, i.e. that the module flag works, but does not affect module activation or de-activation, only cycling.
In the case of the last mass-test, it was the combination of both hard-data gathered from the server and also player feedback, reports, and descriptions that came together to give us a much better and more accurate picture of what the end-user experience was both before and after the new fix was activated. It is this combination of empirical data and player feedback that makes mass-testing so valuable and enables us to rout out the causes of hard-to-find issues, such as lag, much much easier than by doing either one alone. This is where everyone who participates in these tests helps out so much, and really does contribute towards improving the situation much faster than it would be otherwise.
There is a lot more that goes on behind the scenes, with many many hours being spent on analyzing logs and other data sources, plus time carefully reviewing all player feedback. I hope that this has given just a bit more insight into the process and helped answer people's questions about how player participation on the test server really does have a positive affect for everyone in EVE.
Blockers, grumpiness, and finding solutions
Of course, all of this doesn't go off without a hitch. When trying to setup and coordinate public testing with hundreds of players, we certainly run into our fair share of problems. That is exactly why we chose to handle mass-testing in an evolving manner. We must adapt in order to better achieve our desired results: improving EVE. The following is a rundown of the major problems we've faced, along with how we're planning on addressing those issues as we move forward.
Player Attendance
Mass-testing benefits most from having at least 300 players, preferably more. This is because the factors that contribute to "lag" as a whole are generally those of scalability. As a result of this, we simply wont trigger these conditions if we don't get enough people to show up. This means that even if we have a new batch of potential "lag fixes" we cannot really test them, without getting enough people to cause these scalability flaws to manifest. We've tried moving tests to weekends, and at various times off day, all with limited success. We then concluded that this is an issue of perception. Quite simply, if people don't feel that it's a good use of their time, they won't do it. This seems sensible enough, so we're now exploring various types of feedback that we can give to the participants of these tests to make it more readily apparent to everyone how what they're doing is helping. Really, this boils down to my second point, communication.
That said, communication isn't all of it. We're also looking at various ways we can provide better incentive to participate in testing, as well as to make it more fun. We've been considering things like "Singularity rewards," giving game-time for participating in "x" number of tests, turning it into a "Red vs Blue" style rivalry to make it more fun, and loads more. Our goal with this is to make testing more rewarding, in various ways, while still keeping it about the testing and not just about getting stuff, and certainly not unbalancing gameplay on TQ. This is all still being discussed and debated internally, but I wanted to be clear that we are working on it and give some idea of possible options we've been thinking about.
Communication is key
It doesn't take a rocket scientist to figure out that no one likes being kept in the dark. While our test results have been a bit opaque in the past, we're trying to keep that in the past, Since I'm not one who likes excuses I'll just skip to the solution here. We've started working directly with the CSM members to ensure we're keeping open lines of communication, feedback, and information between CCP and the players of EVE about mass-tests, their impact, and their findings. This will manifest in several ways, some sooner than others. Initially this will be mostly on the forums, where we will work with the CSM to refine the post-test reports that we publish to ensure they provide the right information. From there we are also building internal tools that will allow us to publish IGB-viewable pages with information about testing, detailed instructions, FAQ's, guides, etc. We're also looking at trying to put out a short blog after we test big or important changes, all in an effort to keep folks well informed and free from having to guess what's going on.
Staffing and resources
Along with the changes to communication above, we're also ramping up our allocation to mass-testing internally. We're allocating more QA resources into the test events, and building better test scenarios. We're getting more time from programmers to be able to speak directly with the CSM and key others about what exactly the issues are, what testing has found, and what our "next step" is likely to be. All told we're seeing a lot of firm commitment from both our QA and Software teams to not only keep working on the fixes, until they're done, but also to continuing to support these tests and the playerbase as we work through our endless effort to continually improve EVE's overall performance.
Hardware, hardware, hardware
Many of you have no doubt seen the recent blogs about our upgrades to TQ. While upgrades to TQ are great, it presents a different set of challenges to those of us in QA. This comes in the form of hardware, and how much it differes from Singularity (our primary test server, also called SiSi) and Tranquility (our live, production server). On the surface this may not seem like such a big deal, they both work, both let people login and fly spaceships, but that's about where the similarities stop. I could go into all the specifications about how different the two servers are, but that's a lot of techno-mumbo-jumbo that's best left for 2am discussions down at the Brickstore pub. The long and short of it is; right now, Singularity is far behind TQ in hardware. That causes test results to become more and more questionable, especially looking at cluster performance.
Have no fear: upgrades are (almost) here! Our awesome Operations team took up the task of upgrading SiSi to bring it more in-line with TQ, and thus make it a much better test cluster for TQ. These upgrades will happen in phases, but they're actually already started. Now, this will also mean SiSi wont always be available while we upgrade, but it does mean that the situation is already getting better. As of the next mass-test, on August 19th, we should have the test systems running on spiffy new TQ-style hardware. This means that the server should behave much more closely to how nodes on TQ does.
But let's not forget the big hurdle for many players: Patching the Singularity client
Believe me when I say, we're right there along with you in not liking how this currently works. Not only can it be a bit of a task, but it serves as a barrier to entry for participating in the mass-tests. With as often as we update Singularity at times, it can be very difficult to keep your test client up to date, much less find the right patches, get it all applied, and then figure out how to connect to the server. Well, we decided enough is enough and we're in the process of completely changing how this works, all for the better.
We're still in the initial phases of acceptance testing, but we've now got a new "Singularity updater" tool that we think will go a long way to making everyone's lives easier here. This is just a simple executable that you'd download, run, and point at your working TQ client. The tool then takes care of copying the client and updating it to the correct Singularity build, automatically. It will also give you a new link to the client, which connects it directly to Singularity. All of this will be with just three easy clicks for the end-user. We're still working out some kinks, and trying to make it run a bit faster, but we hope to have it out in public use very soon.
Eventually, we plan to expand upon the "Singularity updater" with additional functionality; like diagnostics, bug reporting helpers, logserver helpers, etc.. but that's all still very much in the realm of "Tanis's wet dreams" so we'll see how much of that we can feasibly implement over the next few months vs. what is just wishful thinking.
Plucking the harp one more time
I wanted to bring up the CSM again, before signing off on this blog. Mass-testing is not just about data, or testing fixes, it is about involving the EVE community in assessing the overall quality of EVE. We feel very strongly that EVE's players must be involved, at some level, in the discussion about the quality of the game. You folks are, after all, the ones who play it day in and day out. You spend your free hours in the universe which we've built, so you should always have a say in how good, or bad, you think that universe is working. Obviously, it isn't feasible for us to have one-on-one discussions with everyone, so we have to find some more workable middle ground. We believe we've found a very appropriate one in the CSM. These are the people whom you all elect to represent you to CCP. These are the people who will carry your issues, your gripes, and your kudos to us.
We have struck up a new commitment with the CSM to build a sustainable and open dialog between CCP and the players about the quality and performance of EVE. This means that the CSM will be able to bring concerns to us more readily and that we can, in return, work together to ensure that we effectively communicate about those issues with all of you. This isn't limited to just the current causes of lag, but any issue that may crop up later that makes EVE run poorly, or limits the ability for people to have amazing 1000+ fleet fight once again. We feel this is a very positive change and look forward to working more closely with the CSM towards more effective communication and better mass-tests.
- CCP Tanis
