StacklessIO or: How We Reduced Lag
StacklessIO
For the past two years we have been developing new technology, called StacklessIO, to increase the performance of our network communication infrastructure in EVE. This new network layer reduces network latency and improves performance in high-volume situations, e.g., in fleet-fights and market hubs such as Jita.
On 16 September we successfully deployed StacklessIO to Tranquility. We noticed an astounding, yet expected, measurable difference.
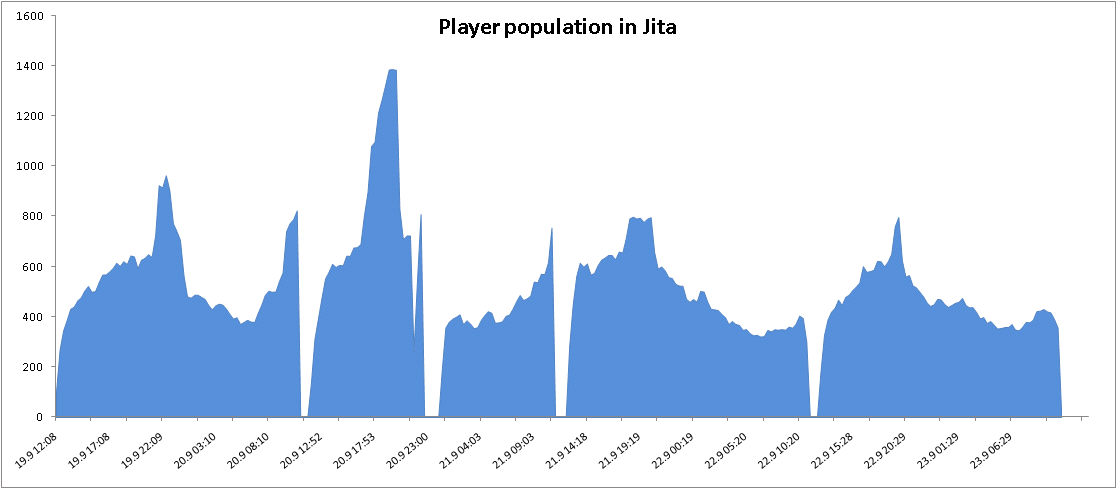
Normally Jita reaches a maximum of about 800-900 pilots on Sundays. On the Friday following the deployment of StacklessIO there were close to 1,000 concurrent pilots in Jita and on Saturday the maximum number reached 1,400. This is more than have ever been in Jita at the same time. Jita could become rather unresponsive at 800-900 pilots but on Sunday it was quite playable and very responsive with 800 pilots. It should continue to be snappier and more responsive in the future.
The Measurements
This spring we saw the fruits of our R&D work when we deployed StacklessIO to Singularity and began measuring the difference.
Confirming suspicion we had had for a long time the Core Server Group team, lead by CCP porkbelly, proved that StacklessIO vastly outperformed the old network technology. They also demonstrated that the old technology could sometimes, under extreme lab conditions, delay network packets in an arbitrary manner for a significant amount of time.
Later CCP Atlas of the EVE Software Group showed that those symptoms also happened in wild with the old technology; although on a smaller scale, then network response to client requests could in some cases be delayed for a few minutes on highly loaded nodes in the cluster. In particular we measured client network communication to the node that hosts Jita.
Since the client and server clocks are synchronised then we called a remote service on the server from the client, the server responded with the global time and we measured the server and client deltas. We also called that same service directly on the server node to measure the service call's processing time, which turned out to be negligible.
What we discovered in our tests is that the server delta was almost identical to the client's received delta so the delay was due to the remote service call taking a long time to reach the server-side service, most likely somewhere in the network layer on the server. The values on the graphs below are seconds.
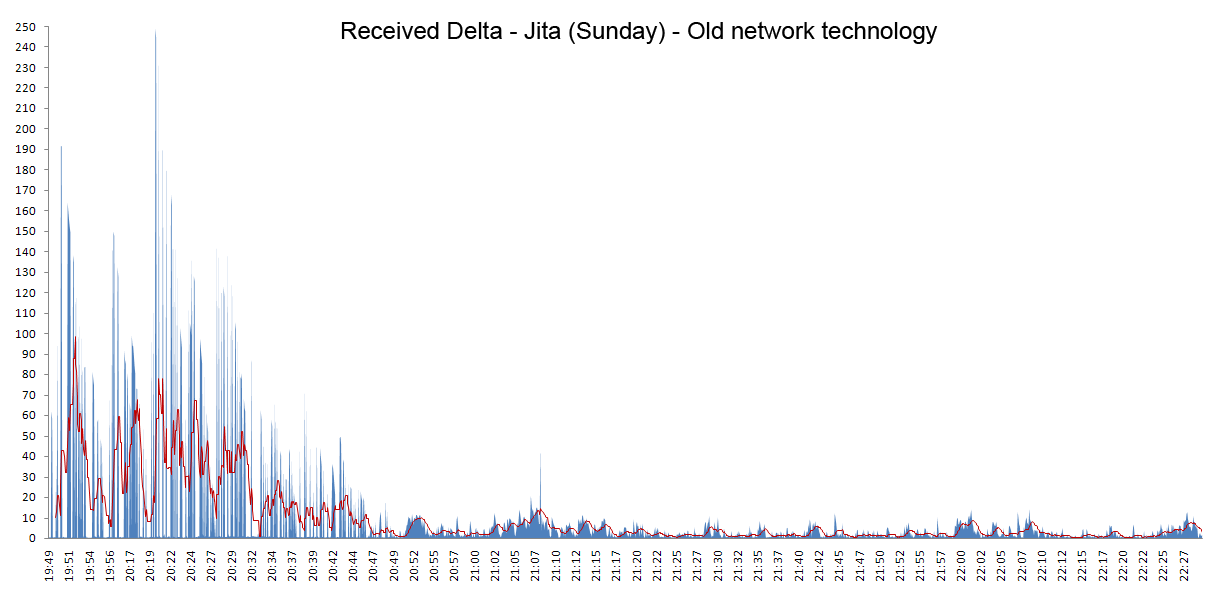
This is a Sunday profile and is very specific to Jita. This was one of the primary reasons why Jita could sometimes become fairly unresponsive on Sunday evenings. It was not uncommon that client requests could take up to 1-2 minutes to reach the service layer on the server, and the requests would be delayed seemingly randomly since for two requests in succession then the first one could be delayed for minutes while the second one would get a response almost immediately. From a player's perspective this would manifest itself in lag and strange client behaviour as requests were delayed and completed by the server much out-of-order.
By comparison, here is Jita with approximately the same number of players, around 800 pilots in local, after the deployment of StacklessIO.
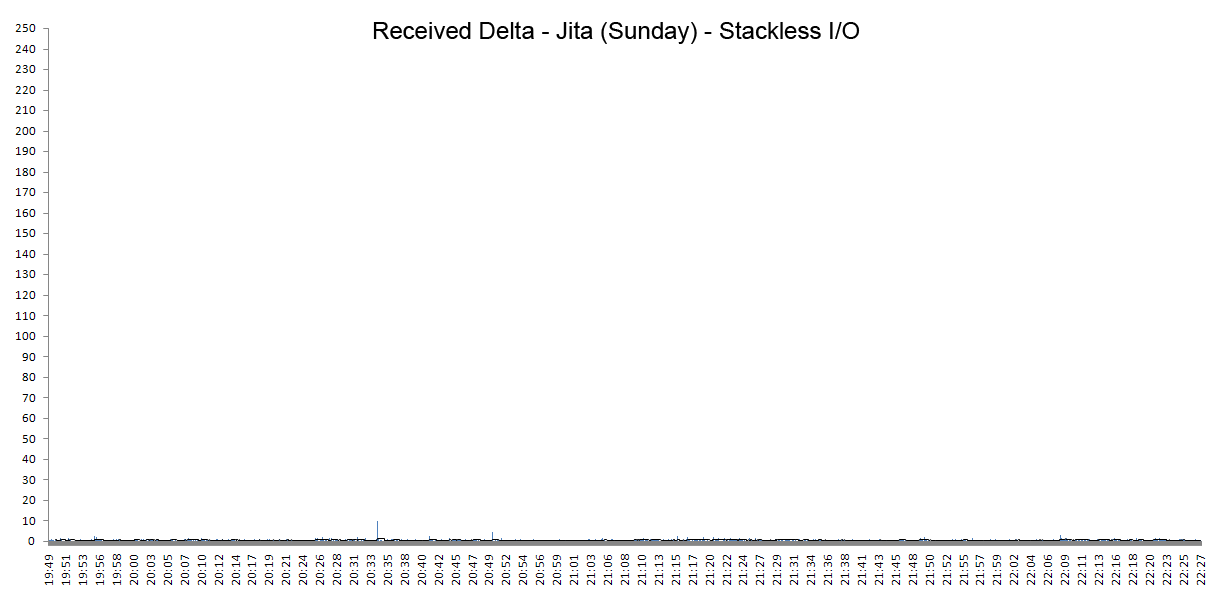
It's very apparent that StacklessIO does not demonstrate any of the earlier issues. There is only one small spike and two small bumps but we must keep in mind that such isolated occurrences could be caused by general network issues on the internet. Since the client/server network communication has to travel through the internet then some delays would be expected depending on general internet health and the particular ISP.
There are no systemic issues anymore as with the old network technology and StacklessIO provides all-around superior performance.
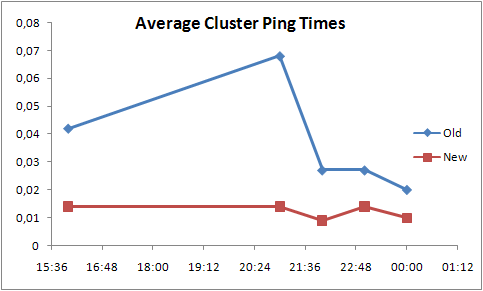
One of the other measurements we did was to ping all nodes in the cluster from a single node to measure network latency within the server cluster. The values in the tables below are seconds.
Ping Pre-StacklessIO
| Time | Minimum | Maximum | Average | Stddev |
| 16:00 | 0.00065 | 3.22 | 0.042 | 0.032 |
| 21:00 | 0.00064 | 4.36 | 0.068 | 0.056 |
| 22:00 | 0.00065 | 1.21 | 0.027 | 0.027 |
| 23:00 | 0.00064 | 4.36 | 0.027 | 0.028 |
| 00:00 | 0.00065 | 1.01 | 0.020 | 0.017 |
Ping StacklessIO
| Time | Minimum | Maximum | Average | Stddev |
| 16:00 | 0.00064 | 2.00 | 0.014 | 0.021 |
| 21:00 | 0.00064 | 1.02 | 0.014 | 0.018 |
| 22:00 | 0.00064 | 0.25 | 0.009 | 0.011 |
| 23:00 | 0.00064 | 1.93 | 0.014 | 0.021 |
| 00:00 | 0.00064 | 1.06 | 0.010 | 0.014 |
From the table we notice that the minimum values are the same before and after. The lowest maximum is approximately the same but overall the maximum values are lower with StacklessIO by approximately a factor of 2 and they are more consistent.
The average values are lower overall with StacklessIO by a factor of 3 and the standard deviation is lower by a factor of 2. Below is a visual representation of the average values.
At 1,400 pilots on Saturday the node hosting Jita ran out of memory and crashed. As crazy as it may sound this was very exciting since we had not been in the position before to be able to have that problem. We immediately turned our attention to solving that challenge and are making significant progress. I will provide information on that specific effort in a dev blog later.
But we have already made good progress on memory optimisation as a part of the StacklessIO technology effort, e.g., memory usage on the proxy servers in the cluster reduced significantly.
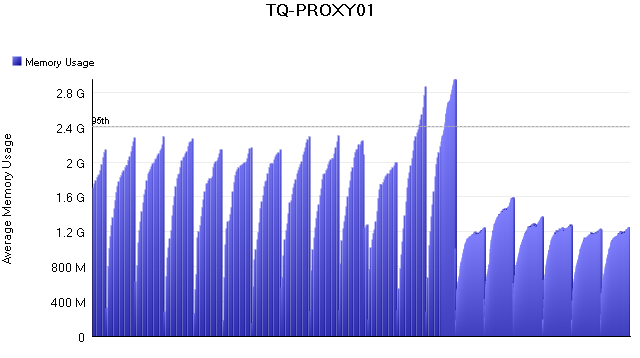
The two tall peaks are memory issues we encountered in the first days after deploying StacklessIO. A task force was put into action and it reduced the memory usage by 50% compared to pre-StacklessIO values.
The graphs and measurements above show primarily statistics for Jita but the benefits of StacklessIO apply everywhere. We measured Jita in particular because we could rely on activity and regular load in Jita for measurements. StacklessIO should have a positive impact on your playing experience, no matter where you are in the EVE universe and no matter what you are doing.
