Well, that was a few people
So we made a bit of a record on October 30th, holding some 3242 players in a single system without the node crashing. This far exceeded our expectations on what a node could handle, and I spent an embarrassing portion of my evening excitedly informing my wife about how high the number in system had gone. Impressive as it was though, I'm sure if you were to ask anyone involved, it was not an ideal gameplay experience.
The next day, we had around 1200 players in the same system, on the same machine, fighting. Similarly, the gameplay was not particularly good. Some say it was worse than the day before. In an important way, they're right, and I want to talk a bit about that today because it's unintuitive and interesting. At least to huge nerds like me.
EVE is a real-time game, but the EVE servers are not real-time systems
That's a heavy statement, so let me expand what I mean. The primary purpose of the EVE server is to respond to user input. A request to start firing a gun, for instance. However, there is no hard deadline on when that request must be handled - simply "as soon as possible would be nice, thanks." That's a good thing, because when the server becomes overloaded, such deadlines would not be possible to keep and extraordinary measures would have to be brought in to fix that, like disconnecting players at random.
The EVE server does have one system that keeps up with real time - the physics simulation, Destiny. It will do everything it can to keep the game world moving at the same time as the clock on the wall. Every other system in the game shares the rest of the available time to do their work. This provides the only priority system present on the server - Destiny simulation is higher priority than everything else. Inside the "everything else" bucket, there is no priority distinction.
So what does all this have to do with the 3242 player fight vs the 1200 player fight?
I'm getting there, but I have to bring up one more concept first: commitment.

No, not that kind of commitment. I'm talking about events that, when handled, are committing to future load. Firing a missile is a good example - saying a missile should be fired is low load in itself (roughly the same as starting a shield booster), but processing that event is committing to actually launching a missile, handling its traversal through space, and if all goes well, its explosion. All of the commitments add up to much more than the initial event. An extreme example is someone getting a kill shot on a ship - the shot itself is relatively cheap compared to the commitment to blow up the ship. Blowing up a ship, after all, involves creating a wreck, deciding which modules should be destroyed, which should become juicy delicious loot, creating a pod, moving the player from the ship to the pod, and making the killmails you all so dearly love.
In an overloaded situation, the throttling mechanism is that new requests from clients get delayed as Destiny and prior commitments get processed. Steady state is reached when the flow of incoming commands is reduced to the point where their processing plus their subsequent commitments fully occupies the available non-Destiny time.
If the Destiny load remains relatively small, we have all the time in the world to process commands and set up commitments. Fire a bunch of guns/missiles, blow up a bunch of ships; we got the time to do those things. But soon the amount of commitments coming from those actions starts to pile up and we get into a situation where new requests are delayed for a very long time due to the amount of load coming from prior commitments. This, in a nutshell, is lag. If it gets too bad, the request for the node to let the rest of the cluster know it's alive will miss its timer and the node will be killed.
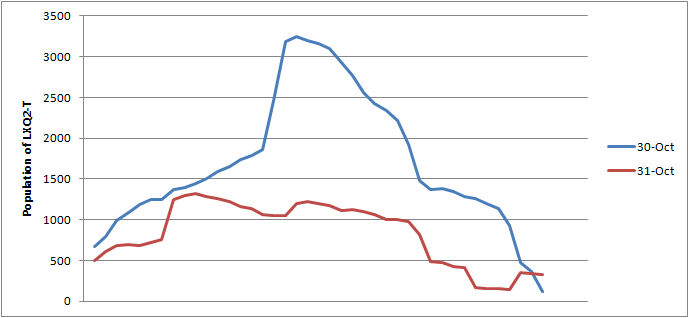
What we saw on the 3242 player engagement was that the Destiny load was huge. Simply gigantic. We've got some bad n^2 behaviors in there that we are in the process of cleaning up, but that's another subject. This huge load starved the "everything else" slice significantly, to the point where the bigger commitments (primarily - ship death and podding) became rare. Without a huge commitment pile sitting on its chest, the node was able to stay reasonably up to date with new requests, making it feel relatively responsive despite being under extreme load.
Anyways, just some musings on an interesting problem - accuracy not guaranteed. I have every reason to believe that someday we'll be able to support flights like the one on October 30th with grace. That we got so many into the system without node death is a good milestone for us in the lag fighting force, but it's a relief more than a cause to celebrate. We're getting there. Expect a blog in the near future with some pretty graphs and stuff having to do with historical server performance and how we've been at making it better in the past few months.
Addendum after this past weekend: The above is all to do with a completely reinforced system - that is to say an EVE server process that is running only one solar system. It all goes a bit nutty when you've got input from multiple systems funneling into one queue. This is why the Fleet Fight Notification Form is so important - it helps us focus the hardware to get as many isolated systems as we can.
In addition, our means to remap loaded systems away from other systems is, shall we say, a bit unstable currently. That's where most of the problem of last weekend came from. Reworking that process to be safer has been in the works for a couple months now by some folks on Team Cobra Kai. They will be testing the results of their efforts so far in mass tests in the very near future, so if you'd like to help make that process less crashy, please attend.
- CCP Veritas
