Fixing Lag: Character Nodes
EVE has a deadly cobra strike force team alpha of extremely dedicated and proficient developers fighting the Lagmonster tooth and nail as their only mission. Through their work and the work of others, there's now, at this moment, a perfect storm within the company and we have a great number of fixes in the pipes that will knock your socks off.
Our hope is that very soon our beloved Tranquility will be able to support fleet fights of a scale that far exceeds anything you've seen before, hopefully going beyond the roof of roughly one thousand on a dedicated node.
That's tough talk, and we mean it. We will continue to go into detail in our ongoing series of dev blogs, some of which have previously been outlined in a dev blog by CCP Zulu. As soon as the optimizations are ready they will be pushed out to Tranquility individually and you will be able to gauge the difference yourself.
Character Nodes
In this blog I am going to talk about one of the optimizations we've been working on over the past few months: Character Nodes which we have already started deploying to Tranquility with phenomenal success.
The EVE Server is architected such a way that functionality is split into logical load balancing units and these units are statically assigned to a node which is a server process running on a single CPU core (since the server process is single-threaded). As long as any individual load balancing unit does not exceed the capacity of that CPU core we're fine since we can just add more nodes if the load becomes too high. However, if a single load balancing unit needs to do more work than a single CPU core can handle then we're in trouble.
A market region (Forge, Lonetrek, etc) is an example of a load balancing unit. We have multiple market regions living on a single node and currently four nodes servicing all the market regions. If the load on the market increases we can just increase the number of nodes dedicated to that task and decrease the number of markets on a given node. What this means is that when you're in Jita and browsing the market, you're not talking to the Jita node at all and don't feel any Jita lag effects (up until the point where you buy or sell something in which case the Jita inventory system gets involved).
Another example of a load balancing unit is a solar system. Typically we will have multiple, even hundreds of solar systems living on a single node. We call these types of nodes Location Nodes. Typically these solar systems have such low load that they can be mapped onto a node with a lot of other systems in the same way as the market is. However, now comes the gotcha: If a single solar system exceeds the capacity of the CPU core we have lost the ability to further balance it.
This is the problem in solar systems like Jita and in systems where fleet fights are occurring. We cannot split the solar system up into more units and spread them out and we cannot spread the work out onto multiple cores. We are effectively stuck between a rock and a hard place (stupid GIL!).
Because of these absolute constraints it's important that any work that doesn't need to be done by the location node is taken elsewhere. Therefore things like planets (in Planetary Interaction), markets, corporations and alliances are load balanced separate of the solar system you're in and if your EVE Client calls these services (such as when you are viewing your corp bulletins) then it's talking to different node than your location node. Your client is at any one time talking to half a dozen different nodes, depending on the call context.
Because of the very strict request-response model that we employ (you click a button (make a request), the server does work, you get a response back) in our business logic a lot of the game systems lend themselves very well to distributed load balancing (e.g. away from your location). However, historically the location node has been viewed as your 'primary' node for a lot of the auxiliary logic that runs on the cluster. If a particular call doesn't have a specific place to go to it will get routed to your location node. Now, that's just lazy.
Today, after years of optimizations the only true remaining bottleneck on the tranquility cluster is the solar system location and we need to shave off every single cpu cycle that we can. With this in mind we introduced the concept of the Character Node in Tyrannis and have been moving services over to this paradigm since.
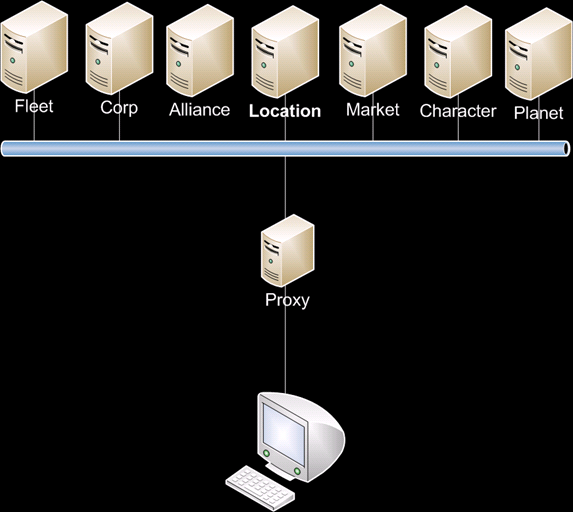
Figure 1: Node configuration
Figure 1 shows what this look like. Calls that would otherwise have gone to 'Location' are now routed to 'Character', which is a set of nodes that is very easily load balanced according to number of logged-in characters. This fits nicely with the schema that is already in place. We need roughly 8 character nodes (out of the total of 204 sol nodes in the cluster) to handle the load and this is very predictable.
Now that most of these changes have been deployed, when your client makes a call for things that aren't directly related to your location, that call will typically be routed to your dedicated character node where your character happily ‘lives' along with tens of thousands of other characters.
Since the work coming from an individual client has a long way to go before it exceeds the capacity of a single CPU core and is easily predictable, we're in a good place. The client still makes the same number of calls to the cluster as before and the amount of work done on the cluster is unchanged. All that is different is that other nodes perform the work.
Changing this isn't very glorious or filled with a lot of eureka! moments. It's mostly just eating your vegetables and rearranging logic. The benefits, however, are substantial since, as it turned out, the majority of the calls that a client makes in a given period can be serviced by any node and therefore should not go to the location node.
The results
Okay, all the wall-of-text above was just to explain how the system works. Now that you've eaten your vegetables it's time for the sugar-laden dessert. Let's see the effect this had on Jita last week, comparing the performance before and after the phase #2 of these changes were deployed to Tranquility on 12 August.
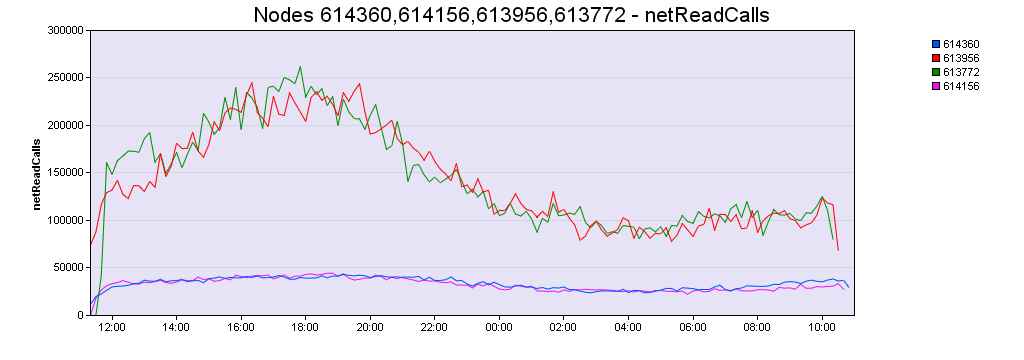
Figure 2: Network traffic on the Jita node
In Figure 2 you can see the number of calls made onto the Jita node in four consecutive runs. After moving some services over to the character nodes, up to 80% of the calls were routed elsewhere freeing Jita up for important things like inventory operations and scams in local.
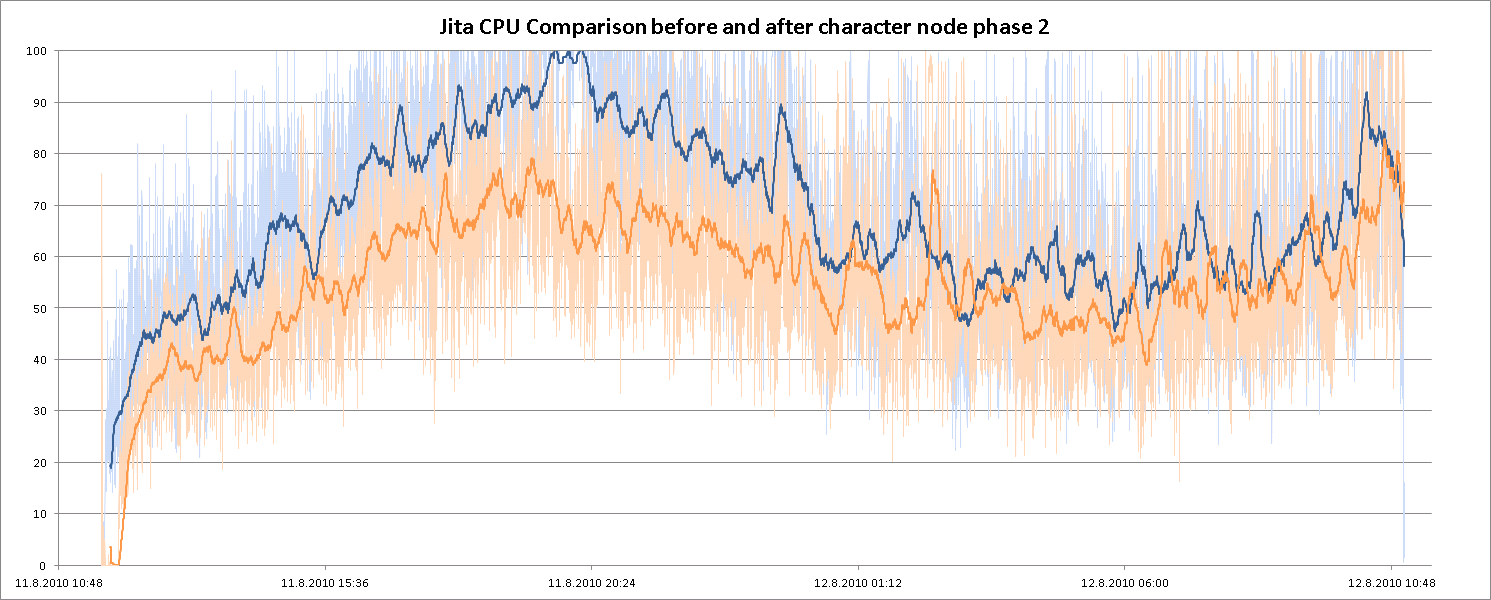
Figure 3: CPU utilization on the Jita node
As expected, moving services away from the Jita node had a good effect on CPU and has allowed us to scale Jita beyond the 1400 pilot limit that has capped its population for a while. Hopefully you should not be towed to another star system when you log in on Sunday evenings for a while.
Even though the metrics that we have gathered are for the Jita node, this change will have a positive effect on all loaded nodes in the cluster--with Jita and Fleet Fight nodes benefiting the most. The reason I use Jita here is that it has a very predictable load pattern whereas fleet fights are anything but. However, the same principles apply. Before this change you would be making something like 5-10 server calls to your location node to finish jumping, each one of these calls could take a long time to complete. Now you'll be making something like 4, with the rest returning very quickly.
We're hoping you'll be able to tell the difference the next time you decide to invade your nearest friendly neighbor. :-)
Also keep in mind that the other benefit of this type of offloading is that you don't "feel" the lag as much. Take Jita for example. If you're just browsing the market you don't notice that it's laggy since you're not talking to that node, you're talking to the market node. With the character node changes that we're doing much of the user experience will be improved greatly since the buttons that you're clicking end up on a lightly loaded node, even if clicking around in space is laggy. This can make a big difference in the overall playing experience.
We have been deploying the character node changes piecemeal to Tranquility throughout August and have a few more going out over the next few weeks. These should give you better performance in fleet fights as well as allow us to push Jita's concurrent player boundaries further.
This is all well and good but keep in mind that ‘lag' hasn't been ‘fixed' once and for all and it might not be in the foreseeable future, but we are pushing the boundaries of the cluster more aggressively these days than we have been for a while. Like I mentioned before, this is just one of the many things that we are working on right now. More services are being moved to character nodes this autumn and we will have plenty of more awesome fixes aimed at fleet fights coming in over the next weeks and months.
Fleet fight tests on Singularity
As stated before, it is very important for us to get as many people as possible involved when we are testing on the Singularity test server (SiSi). Please join in when the tests are advertised and help us test the performance improvements so that they can be deployed onto Tranquility as quickly as possible.
A word about fleet fight notifications
A fleet fight which happens on a node with a hundred other systems is not a good experience for anyone involved since often times the node only has 30% left of its CPU capacity when the fight starts. You can help make sure that the solar system you will be fighting in is on a dedicated node.
Use the Fleet Fight Notification form to let us know about a pending fleet fight. Sending in a petition is not the right way to report this, you must use the form. If you report the fight well in advance we can make sure that the fight is as smooth as we can make it.
Jon Bjarnason
Technical Director
EVE Online, CCP Games
